暗号資産市場は、その極端な変動性で知られており、投資家にとって大きな機会を提供する一方で、かなりのリスクも伴います。正確な価格予測は情報に基づいた投資判断にとって重要です。しかし、従来の金融分析手法は暗号資産市場の複雑さと急激な変動に対処するのが難しいことがよくあります。近年、機械学習の進歩により、特に暗号資産価格予測の金融時系列予測に強力なツールが提供されています。
機械学習アルゴリズムは、大量の歴史的価格データやその他関連情報から学習し、人間が検出するのが難しいパターンを特定することができます。様々な機械学習モデルの中で、再帰ニューラルネットワーク(RNN)やその派生形態である長期・短期記憶(LSTM)やトランスフォーマーモデルは、直列データを扱う卓越した能力で広く注目され、暗号資産価格の予測において増大する潜在能力を示しています。本記事では、暗号資産価格予測のための機械学習モデルについて詳細な分析を提供し、LSTMとトランスフォーマーアプリケーションの比較に焦点を当てています。また、多様なデータソースの統合がモデルの性能を向上させる方法を探り、ブラックスワンイベントがモデルの安定性に与える影響についても検討しています。
暗号資産価格予測における機械学習の応用
機械学習の基本的な考え方は、コンピュータに大規模なデータセットから学習させ、学習したパターンに基づいて予測させることです。これらのアルゴリズムは、過去の価格変動、取引量、およびその他の関連データを分析し、隠れたトレンドやパターンを見つけ出します。一般的な手法には、回帰分析、意思決定木、およびニューラルネットワークがあり、これらはすべて暗号資産価格予測モデルの構築に広く使用されています。
大部分の研究は、暗号資産価格の予測の初期段階では、従来の統計的手法に依存していました。例えば、2017年頃、ディープラーニングが広まる前には、多くの研究がARIMAモデルを使用してビットコインの価格トレンドを予測しました。Dong、Li、Gong(2017)による代表的な研究では、ARIMAモデルを使用してビットコインのボラティリティを分析し、従来のモデルが線形トレンドを捉える際の安定性と信頼性を示しています。
技術の進歩により、2020年までに、深層学習手法は金融時系列予測において画期的な成果を示し始めました。特に、Long Short-Term Memory(LSTM)ネットワークは、時系列データの長期依存関係を捉える能力により人気を博しました。研究するPatelら(2019)による研究は、当時のBitcoin価格の予測におけるLSTMの利点を証明し、重要な進歩を示しました。
2023年までに、Transformerモデルは、一度にデータシーケンス全体の関係を捉える能力を持つ独自のセルフアテンションメカニズムを備えているため、金融時系列の予測にますます適用されるようになりました。たとえば、Zhaoらの2023年研究「注意!暗号資産価格予測のセンチメントに焦点を当てたTransformerが正常にソーシャルメディアのセンチメントデータと統合され、暗号資産価格トレンド予測の精度が大幅に向上し、この分野における重要なマイルストーンを記録しました。」

暗号資産予測技術のマイルストーン(出典:Gate Learn Creator John)
多くの機械学習モデルの中で、特に再帰ニューラルネットワーク(RNN)およびその高度なバージョンであるLSTMやTransformerなどの深層学習モデルは、時系列データの処理において著しい利点を示しています。 RNNは、過去の段階から情報を後の段階に渡すことで、効果的に時間的依存関係を捉えるように設計されています。 ただし、伝統的なRNNは、長いシーケンスを扱う際に「勾配消失」問題に苦しむため、古いが重要な情報が徐々に失われてしまいます。 これを解決するために、LSTMはRNNにメモリセルとゲートメカニズムを導入し、主要情報の長期保持と長期的依存関係のモデリングを向上させています。 歴史的な暗号資産価格などの金融データは強い時間的特性を示すため、LSTMモデルはこのようなトレンドを予測するのに特に適しています。
一方、Transformerモデルは元々言語処理用に開発されました。その自己注意メカニズムにより、モデルはデータシーケンス全体の関係を一度に考慮することができ、ステップごとに処理するのではなく、同時に処理できます。このアーキテクチャにより、Transformersは複雑な時間依存関係を持つ金融データを予測する上で非常に大きな潜在能力を持っています。
予測モデルの比較
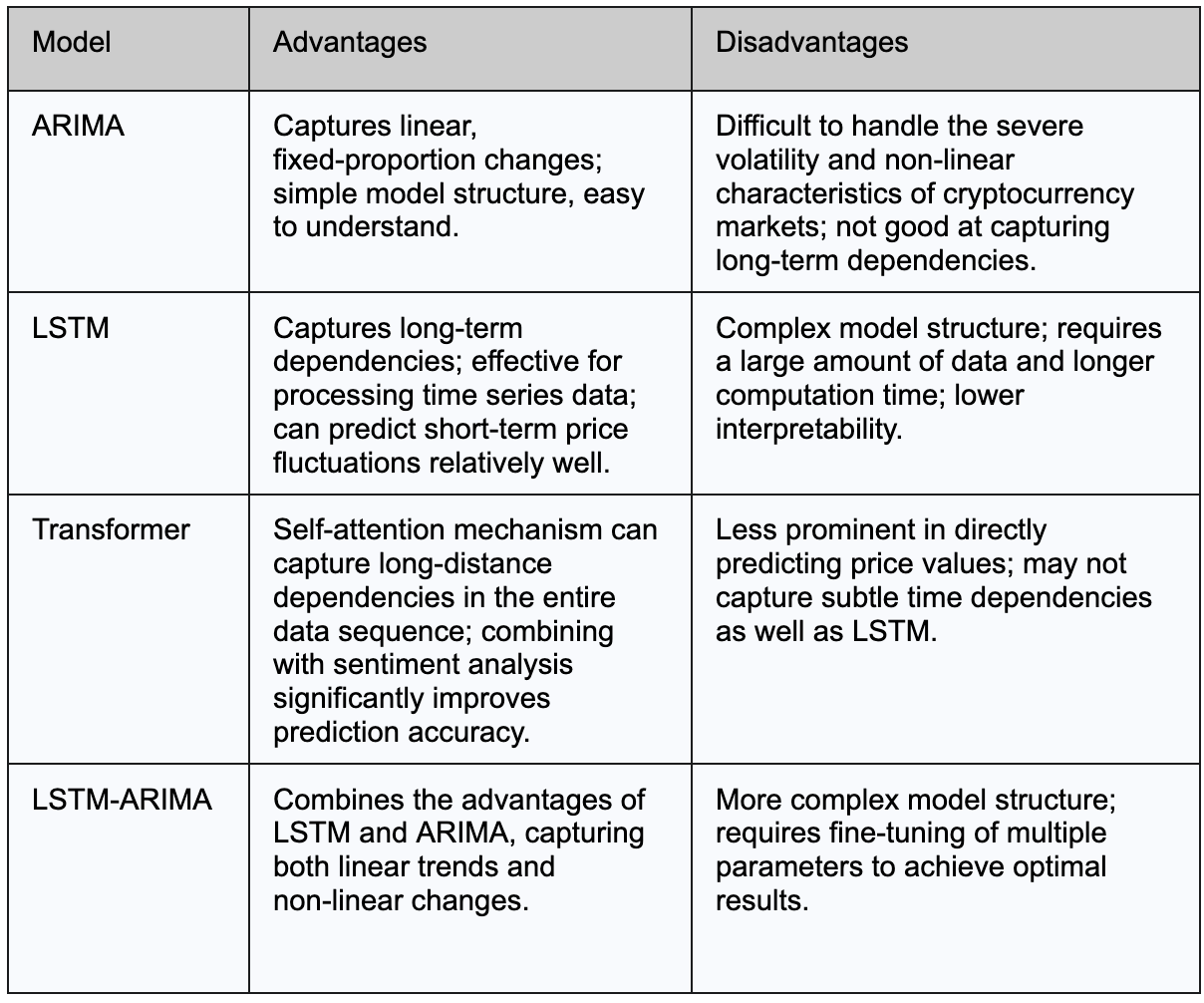
暗号資産の価格予測では、伝統的なARIMAのようなモデルが深層学習モデルと並んでベースラインとしてよく使用されます。 ARIMAはデータ内の線形トレンドと一貫した比例変化を捉えるよう設計されており、多くの予測タスクで優れた性能を発揮します。 ただし、暗号資産価格の高いボラティリティと複雑さの性質により、ARIMAの線形仮定はしばしば不十分です。研究によると深層学習モデルは一般的に非線形および大幅に変動する市場でより正確な予測を提供することが一般的です。
深層学習アプローチの中で、ビットコイン価格を予測する上でLSTMとTransformerモデルを比較した研究では、LSTMが短期価格変動の微細な詳細を捉える際に優れた性能を発揮することが分かりました。この優位性は、LSTMのメモリメカニズムによるものであり、短期依存関係をより効果的かつ安定してモデル化することができるからです。LSTMは短期予測の精度で優れているかもしれませんが、Transformerモデルは依然として非常に競争力があります。Twitterなどからの感情分析などの追加のコンテキストデータを組み合わせることで、Transformersはより広範な市場理解を提供し、予測パフォーマンスを著しく向上させることができます。
さらに、一部の研究では、LSTM-ARIMAなどの伝統的な統計手法と深層学習を組み合わせたハイブリッドモデルを探究してきました。これらのハイブリッドモデルは、データ内の線形および非線形パターンの両方を捉えることを目指し、予測精度とモデルの頑健性をさらに向上させることを目指しています。
以下の表は、ビットコイン価格予測におけるARIMA、LSTM、およびTransformerモデルの主な利点と欠点を要約しています:
特徴エンジニアリングを使用して予測精度を向上させる
暗号資産価格を予測する際、我々は過去の価格データだけに頼らず、より正確な予測を行うために追加の貴重な情報も取り入れます。このプロセスは特徴量エンジニアリングと呼ばれ、予測性能を高めるデータ「特徴」を整理して構築することを含みます。
共通の特徴データソース
オンチェーンデータ
オンチェーンデータブロックチェーンに記録されたすべての取引およびアクティビティ情報を指します。取引量、アクティブアドレスの数などが含まれます。マイニング難易度、ハッシュレートこれらの指標は、市場の供給と需要のダイナミクスや全体的なネットワーク活動を直接反映しており、価格予測に非常に価値があります。たとえば、取引量の急増は市場のセンチメントの変化を示す可能性があり、アクティブアドレスの増加は広範な採用を示す可能性があり、価格を押し上げることがあります。
このようなデータは、通常、ブロックチェーンエクスプローラーAPIや専門のデータプロバイダーを介してアクセスされます。Glassnode と Coin MetricsPythonのrequestsライブラリを使用して、APIを呼び出したり、解析用に直接CSVファイルをダウンロードしたりできます。
ソーシャルメディアセンチメントインジケーター
Platforms like Santiment暗号資産に対する市場参加者のセンチメントを評価するために、TwitterやRedditなどのソースからテキストコンテンツを分析します。さらに、自然言語処理(NLP)の技術を用いてセンチメント分析などの手法を適用し、このテキストをセンチメント指標に変換します。これらの指標は投資家の意見や期待を反映し、価格予測のための貴重な情報を提供します。たとえば、ソーシャルメディアで圧倒的にポジティブなセンチメントがあると、より多くの投資家を引きつけて価格を押し上げる可能性がありますが、ネガティブなセンチメントは売り圧力を引き起こす可能性があります。Santimentのようなプラットフォームでは、開発者がセンチメントデータを予測モデルに統合するためのAPIやツールも提供されています。研究によるとSNSセンチメント分析を取り入れることで、特に短期予測において、暗号資産価格予測モデルのパフォーマンスを大幅に向上させることができます。

Santimentは、暗号通貨に関する市場参加者の見解に関するセンチメントデータを提供できます(ソース:Santiment)
マクロ経済要因
金利、インフレ率、GDP成長率、失業率などのマクロ経済指標は、暗号資産の価格にも影響を与えます。これらの要因は投資家のリスク選好や資本流れに影響を与えます。例えば、金利が上昇すると、投資家は暗号資産などの高リスク資産から安全な選択肢に資金を移す可能性があり、価格が下落することがあります。一方、インフレが上昇すると、投資家は価値を保全する資産を求める可能性があります。ビットコインは時折、インフレへのヘッジと見なされることがあります。
利子、インフレ、GDP成長、失業率などのデータは、通常、国家政府や世界銀行、IMFのような国際機関から入手することができます。これらのデータセットは、通常、CSV形式やJSON形式で提供され、pandas_datareaderのようなPythonライブラリを介してアクセスすることができます。
以下の表は、一般的に使用されるオンチェーンデータ、ソーシャルメディアのセンチメント指標、およびマクロ経済要因をまとめ、それらが暗号資産価格にどのように影響するかを示しています。

機能データの統合方法
一般的に、このプロセスはいくつかのステップに分解できます:
1. データのクリーニングと標準化
異なるソースからのデータは異なる形式を持つ場合があり、一部が欠落しているか一貫性がない場合があります。そのような場合、データクリーニングが必要です。たとえば、すべてのデータを同じ日付形式に変換したり、欠落しているデータを補ったり、データを標準化して比較しやすくすることがあります。
2. データ 統合
クリーニング後、さまざまなソースからのデータが日付に基づいて統合され、各日の市場状況を示す完全なデータセットが作成されます。
3. モデル入力の構築
最終的に、この統合されたデータは、モデルが理解できる形式に変換されます。たとえば、過去60日間のデータに基づいて今日の価格を予測するモデルを作成したい場合、それらの60日間のデータをリスト(または行列)に整理して、モデルの入力として使用します。モデルは、このデータ内の関係を学習して将来の価格トレンドを予測します。
そのモデルは、この特徴量エンジニアリングプロセスを通じてより包括的な情報を活用して予測精度を向上させることができます。
オープンソースプロジェクトの例
GitHubには多くの人気のあるオープンソースの暗号資産価格予測プロジェクトがあります。これらのプロジェクトは、さまざまな機械学習や深層学習モデルを使用して、異なる暗号資産の価格トレンドを予測しています。
ほとんどのプロジェクトは、人気のある深層学習フレームワークを利用していますTensorFlowまたはKeras過去の価格データからパターンを学習し、未来の価格動向を予測するためのモデルを構築し、トレーニングする。通常、このプロセス全体には、データの前処理(過去の価格データの整理および標準化など)、モデル構築(LSTMレイヤーおよび他の必要なレイヤーの定義)、モデルのトレーニング(大規模なデータセットを通じてモデルパラメータを調整し、予測エラーを減らす)、最終評価および予測結果の可視化が含まれる。
暗号資産価格を予測するためにディープラーニング技術を使用するプロジェクトの1つは、Dat-TG/Cryptocurrency-Price-Prediction.
このプロジェクトの主な目標は、LSTMモデルを使用して、ビットコイン(BTC-USD)、イーサリアム(ETH-USD)、カルダノ(ADA-USD)の終値を予測し、投資家が市場トレンドをより良く理解するのに役立てることです。ユーザーはGitHubリポジトリをクローンし、提供された指示に従ってローカルでアプリケーションを実行できます。

BTCプロジェクトの予測結果(出典: 暗号資産価格ダッシュボード)
このプロジェクトのコード構造は明確であり、データの取得、モデルのトレーニング、Webアプリケーションの実行には別々のスクリプトとJupyter Notebooksがあります。プロジェクトディレクトリ構造と内部コード, 予測モデル構築プロセスは次のようになります:
- データはYahoo Financeからダウンロードされ、その後Pandasを使用してクリーニングおよび整理が行われます。日付形式の標準化や欠損値の補完などのタスクが含まれます。
- 処理されたデータは、「スライディングウィンドウ」として生成されます — 過去60日間のデータを利用して、61日目の価格を予測します。
- そのデータは、LSTM(Long Short-Term Memory)を使用して構築されたモデルに入力されます。 LSTMは短期および長期の価格変動を効果的に記憶し、価格トレンドを予測するのに適しています。
- 予測結果と実際の価格は、Plotly Dashを使用してさまざまなチャートで表示され、ドロップダウンメニューを介してユーザーが異なる暗号資産やテクニカルインジケータを選択し、チャートをリアルタイムで更新することができます。

プロジェクトディレクトリ構造(ソース:暗号資産-価格-予測)
暗号資産価格予測モデルリスク分析
モデルの安定性へのブラックスワンイベントの影響
ブラックスワンの出来事は非常に稀で予測不能であり、大きな影響を与えます。これらの出来事は通常、従来の予測モデルの想定を超えており、重大な市場の混乱を引き起こす可能性があります。典型的な例は、ルナクラッシュ2022年5月。
アルゴリズムステーブルコインプロジェクトとしてのルナは、安定性を求めて姉妹トークンのLUNAとの複雑なメカニズムに依存していました。2022年5月初旬、ルナのステーブルコインUSTは米ドルから切り離され、投資家がパニック売りを引き起こしました。アルゴリズムメカニズムの欠陥により、USTの崩壊がLUNAの供給を急激に増加させました。数日で、LUNAの価格は80ドル近くからほぼゼロに急落し、市場価値数千億ドルを逃れる結果となりました。これにより関係者の投資家には大きな損失が生じ、仮想通貨市場のシステムリスクに対する幅広い懸念が引き起こされました。
したがって、ブラックスワンイベントが発生すると、過去のデータで訓練された従来の機械学習モデルは、そのような極端な状況に遭遇したことがない可能性が高く、正確な予測を行うことができないか、誤った結果を生み出す可能性があります。
モデルの固有リスク
ブラックスワンのイベントに加えて、モデル自体に固有のリスクも意識する必要があります。これらは徐々に蓄積され、日常の利用において予測精度に影響を及ぼす可能性があります。
(1) データのスキューと外れ値
金融時系列データでは、データはしばしばスキューを示すか、外れ値を含んでいます。適切なデータ前処理が行われていない場合、モデルのトレーニングプロセスはノイズによって妨害され、予測の正確さに影響を与える可能性があります。
(2) 単純化されたモデルと不十分な検証
一部の研究は、市場の非線形要因を無視し、線形トレンドを捉えるためにARIMAモデルのみを使用するなど、モデル構築時に単一の数学的構造に過度に依存する可能性があります。これにより、モデルが過度に単純化されることがあります。さらに、十分なモデル検証がないと、過度に楽観的なバックテストのパフォーマンスが得られる一方で、実際の適用において予測結果が悪化することがあります(たとえば、オーバーフィッティング歴史的データでは優れたパフォーマンスを発揮しますが、実際の使用ではかなりの偏差が生じます)。
(3) APIデータレイテンシーリスク
ライブトレードでは、モデルがリアルタイムのデータを取得するためにAPIに依存している場合、APIの遅延やデータのタイムリーな更新の失敗が直接モデルの動作や予測結果に影響を与え、ライブトレードの失敗につながる可能性があります。
予測モデルの安定性を向上させるための措置
上記のリスクに直面して、モデルの安定性を向上させるために対応策を講じる必要があります。特に以下の戦略が重要です:
(1)多様なデータソースとデータの前処理
複数のデータソース(過去の価格、取引高、ソーシャルセンチメントデータなど)を組み合わせることで、単一のモデルの欠点を補うことができます。厳密なデータクリーニング、変換、分割を行うべきです。このアプローチにより、モデルの汎化能力が向上し、データの偏りや外れ値によるリスクが軽減されます。
(2) 適切なモデル評価メトリクスの選択
モデル構築プロセスでは、データの特性(MAPE、RMSE、AIC、BICなど)に基づいて適切な評価指標を選択し、過剰適合を回避するために、モデルのパフォーマンスを総合的に評価することが重要です。定期的な交差検証とローリング予測も、モデルの堅牢性を向上させるために重要なステップです。
(3) モデルの検証と繰り返し
モデルが確立されると、残差分析と異常検出メカニズムを使用して徹底的に検証されるべきです。予測戦略は、市場の変化に基づいて継続的に調整されるべきです。たとえば、現在の市況に応じてモデルパラメータを動的に調整するためにコンテキスト感知学習を導入することは1つのアプローチです。さらに、深層学習モデルと伝統的なモデルを組み合わせてハイブリッドモデルを構築することは、予測精度と安定性を向上させるための効果的な方法です。
コンプライアンスリスクへの注意
最後に、技術リスクに加えて、センチメントデータなどの非伝統的なデータソースを使用する際には、データプライバシーおよびコンプライアンスリスクも考慮する必要があります。たとえば、米国証券取引委員会(SEC)感情データの収集と利用に関する厳格な審査要件を持ち、プライバシー問題から生じる法的リスクを防止します。
このことは、データ収集プロセス中に、ユーザー名、個人情報などの個人を特定できる情報を匿名化する必要があることを意味しています。これは、個人のプライバシーが露出されることを防ぎつつ、データの不適切な使用を回避することを目的としています。さらに、収集されたデータソースが適正であり、不正な手段(無許可のWebスクレイピングなど)で入手されていないことを確認することが重要です。また、データ収集と使用の方法を公開し、投資家や規制機関がデータがどのように処理および適用されるかを理解できるようにすることが不可欠です。この透明性は、データが市場センチメントを操作するために使用されるのを防ぐのに役立ちます。
結論と将来展望
結論として、機械学習ベースの暗号資産価格予測モデルは、市場の変動性と複雑さに対処する上で大きな潜在能力を示しています。リスク管理戦略を統合し、新しいモデルアーキテクチャやデータ統合手法を継続的に探求することが、将来の暗号資産価格予測の発展にとって重要な方向性となります。機械学習技術の進歩とともに、より正確で安定した暗号資産価格予測モデルが登場し、投資家に強力な意思決定サポートを提供すると考えています。
共有
内容
マルチコイン・キャピタルは2月以降、重要なZECポジションを構築していると共同創業者が語る
テザーのCEOが今週中に提供されるAI研究の画期的なブレークスルーを発表
Firedancer 1.0 バリデーションクライアントがSolanaで本番デプロイメントを起動
TONウォレットのUQDvWのUTYAポジションが、18か月前の$19.8Kの買い付けから$1.37Mへ急騰し、先週は68倍に伸長
スーパー・マイクロは第4四半期の見通しで18%上昇;EPS見通し65〜79セントが予想を上回る


関連記事

スマートレバレッジに関連するリスクにはどのようなものがあるのでしょうか?

スマートレバレッジを活用する際の最適なシナリオとトレーディング戦略


Gate ETFの運用方法について、純資産価値(NAV)メカニズムから自動リバランスまで詳しく解説します。

ファンダメンタル分析とは何か
