Рынок криптовалют известен своей крайней волатильностью, представляя значительные возможности для инвесторов, но также значительные риски. Точное прогнозирование цен важно для обоснованных инвестиционных решений. Однако традиционные методы финансового анализа часто испытывают трудности с учетом сложности и быстрых изменений на рынке криптовалют. В последние годы с развитием машинного обучения появились мощные инструменты для прогнозирования финансовых временных рядов, особенно в прогнозировании цен на криптовалюты.
Алгоритмы машинного обучения могут изучать большие объемы исторических данных о ценах и другую актуальную информацию, выявляя сложные закономерности, которые люди не могут обнаружить. Среди различных моделей машинного обучения Рекуррентные нейронные сети (RNN) и их варианты, такие как долгосрочная краткосрочная память (LSTM) и модели Трансформера, получили широкое внимание благодаря своей уникальной способности обрабатывать последовательные данные, проявляя все больший потенциал в прогнозировании цен на криптовалюту. В этой статье предлагается глубокий анализ моделей, основанных на машинном обучении, для прогнозирования цен криптовалют, с акцентом на сравнение применения LSTM и Трансформера. Также рассматривается, как интеграция разнообразных источников данных может повысить производительность модели и изучается влияние событий черного лебедя на стабильность модели.
Применение машинного обучения в прогнозировании цен криптовалюты
Основная идея машинного обучения заключается в том, чтобы позволить компьютерам изучать большие наборы данных и делать прогнозы на основе выявленных закономерностей. Эти алгоритмы анализируют исторические изменения цен, объемы торгов и другие связанные данные для выявления скрытых тенденций и закономерностей. Распространенные подходы включают в себя анализ регрессии, деревья решений и нейронные сети, которые широко используются при построении моделей прогнозирования цен криптовалют.
Большинство исследований в начальной стадии прогнозирования цен на криптовалюту полагались на традиционные статистические методы. Например, около 2017 года, до широкого распространения глубокого обучения, многие исследования использовали модели ARIMA для прогнозирования тенденций цен на криптовалюты, такие как Биткойн. Представительное исследование Донга, Ли и Гонга (2017) использовало модель ARIMA для анализа волатильности Биткойна, демонстрируя стабильность и надежность традиционных моделей в улавливании линейных тенденций.
С технологическими достижениями глубокое обучение начало показывать прорывные результаты в прогнозировании финансовых временных рядов к 2020 году. В частности, сети долгой краткосрочной памяти (LSTM) стали популярными из-за их способности улавливать долгосрочные зависимости в данных временных рядов. AучитьсяПо данным Патель и др. (2019) было доказано преимущество LSTM в прогнозировании цен на биткойн, что является значительным прогрессом на тот момент.
К 2023 году модели Transformer с их уникальными механизмами самовнимания, способными захватывать отношения по всей последовательности данных одновременно, все чаще применялись для прогнозирования финансовых временных рядов. Например, 2023 года Чжао и др.учиться«Внимание! Трансформатор с настроением по предсказанию цен на криптовалюту» успешно интегрировал модели трансформаторов с данными о настроениях в социальных сетях, значительно улучшив точность прогнозов трендов цен на криптовалюту, отметив важный вех в этой области.

Вехи в технологии прогнозирования криптовалют (Источник: Создатель Gate Learn Джон)
Среди множества моделей машинного обучения модели глубокого обучения, в частности рекуррентные нейронные сети (RNN) и их продвинутые версии, LSTM и Transformer, продемонстрировали значительные преимущества в обработке данных временных рядов. RNN специально разработаны для обработки последовательных данных путем передачи информации с более ранних шагов на более поздние, эффективно фиксируя зависимости в разных точках времени. Тем не менее, традиционные RNN борются с проблемой «исчезающего градиента» при работе с длинными последовательностями, что приводит к постепенной потере старой, но важной информации. Чтобы решить эту проблему, LSTM вводит ячейки памяти и механизмы стробирования поверх РНС, обеспечивая долгосрочное хранение ключевой информации и лучшее моделирование долгосрочных зависимостей. Поскольку финансовые данные, такие как исторические цены на криптовалюты, демонстрируют сильные временные характеристики, модели LSTM особенно хорошо подходят для прогнозирования таких тенденций.
С другой стороны, модели-трансформеры изначально были разработаны для обработки языка. Их механизм самовнимания позволяет модели рассматривать отношения во всей последовательности данных одновременно, а не обрабатывать их пошагово. Эта архитектура дает Трансформерам огромный потенциал в предсказании финансовых данных с комплексными временными зависимостями.
Сравнение моделей прогнозирования
Традиционные модели, такие как ARIMA, часто используются в качестве базовых моделей наряду с моделями глубокого обучения при прогнозировании цен криптовалют. ARIMA разработана для выявления линейных тенденций и постоянных пропорциональных изменений в данных, успешно справляется с многими задачами прогнозирования. Однако из-за высокой волатильности и сложной природы цен на криптовалюты линейные предположения ARIMA часто оказываются недостаточными.Исследования показаличто модели глубокого обучения обычно обеспечивают более точные прогнозы на нелинейных и сильно флуктуирующих рынках.
Среди подходов глубокого обучения исследование, сравнивающее модели LSTM и Transformer в прогнозировании цен на биткойн, показало, что LSTM работает лучше при улавливании более детальных нюансов краткосрочных изменений цен. Это преимущество в первую очередь обусловлено механизмом памяти LSTM, который позволяет ему более эффективно и стабильно моделировать краткосрочные зависимости. В то время как LSTM может превзойти в точности краткосрочного прогнозирования, модели Transformer остаются высококонкурентоспособными. Когда они дополняются дополнительными контекстными данными, такими как анализ настроений в Twitter, Transformer могут предложить более широкое понимание рынка, значительно улучшая прогностическую производительность.
Более того, некоторые исследования исследовали гибридные модели, которые сочетают глубокое обучение с традиционными статистическими подходами, такими как LSTM-ARIMA. Целью этих гибридных моделей является захват как линейных, так и нелинейных закономерностей в данных, что дополнительно повышает точность прогнозирования и устойчивость модели.
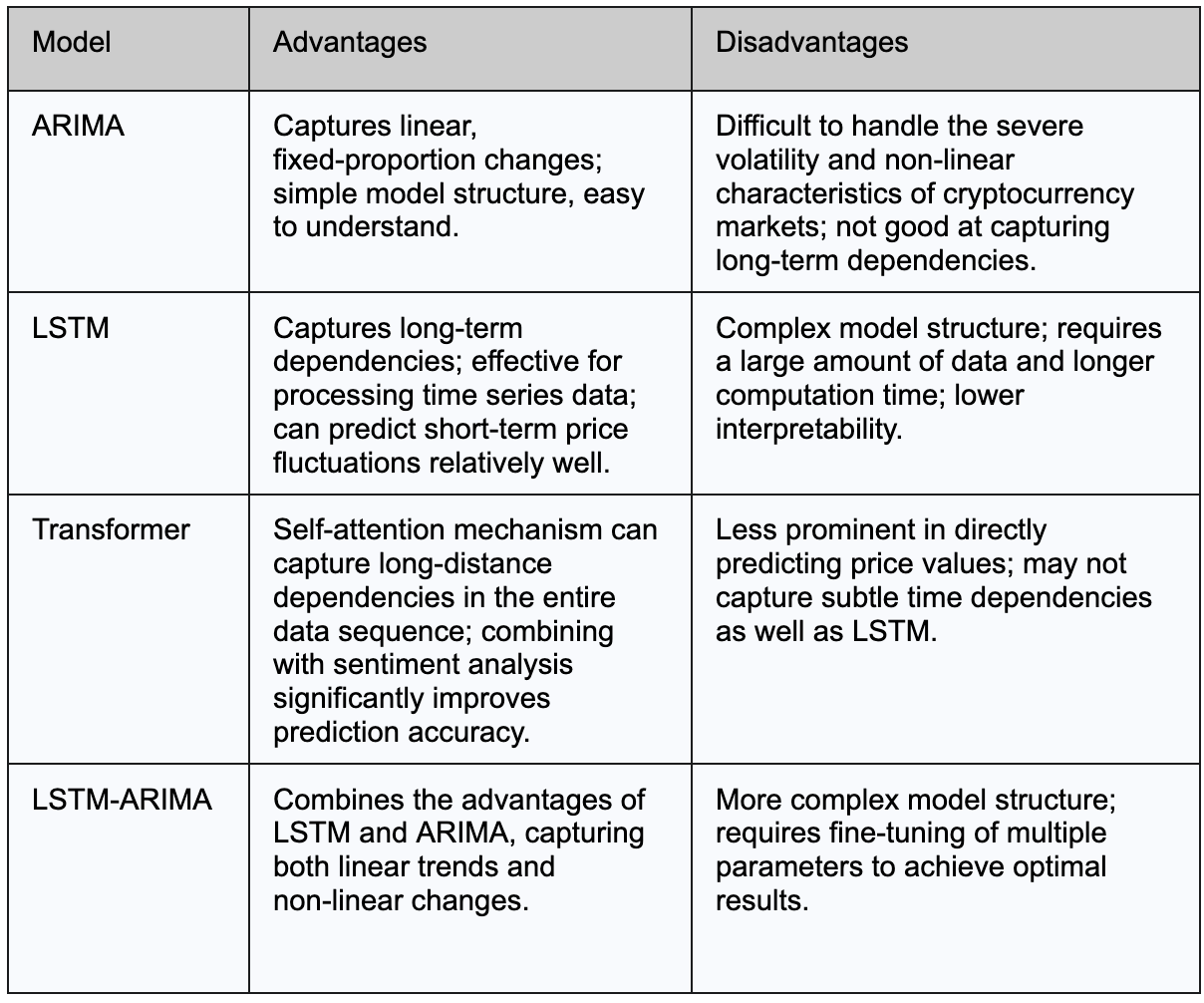
В таблице ниже кратко изложены основные преимущества и недостатки моделей ARIMA, LSTM и Transformer в прогнозировании цен на биткоин:
Улучшение точности прогнозирования с помощью инженерии признаков
При прогнозировании цен криптовалют мы не полагаемся исключительно на исторические данные о ценах - мы также включаем дополнительную ценную информацию, чтобы помочь моделям делать более точные прогнозы. Этот процесс называется инженерией признаков, включающий организацию и конструирование данных "признаков", которые улучшают производительность прогнозирования.
Общие источники данных о функциях
Данные на цепи
Данные on-chainотносится ко всей транзакционной и активной информации, записанной в блокчейне, включая объем торгов, количество активных адресов,сложность майнинга, и хешрейт. Эти метрики напрямую отражают динамику рыночного спроса и предложения и общую активность сети, что делает их очень ценными для прогнозирования цен. Например, значительный скачок объема торговли может сигнализировать о смене рыночного настроения, в то время как увеличение активных адресов может указывать на более широкое принятие, что потенциально может подтолкнуть цены вверх.
Такие данные обычно доступны через API-интерфейсы блокчейн-эксплореров или специализированных поставщиков данных, таких как GlassnodeиМонетные метрики. Вы можете использовать библиотеку requests Python для вызова API или непосредственной загрузки файлов CSV для анализа.
Индикаторы настроений в социальных сетях
Платформы, подобные Santimentанализировать текстовое содержимое из источников, таких как Twitter и Reddit, чтобы оценить настроения участников рынка по отношению к криптовалютам. Они также применяют техники обработки естественного языка (NLP), такие как анализ настроений, чтобы преобразовать этот текст в показатели настроения. Эти показатели отражают мнения и ожидания инвесторов, предоставляя ценную информацию для прогнозирования цен. Например, преимущественно положительное настроение в социальных сетях может привлечь больше инвесторов и поднять цены, в то время как негативное настроение может вызвать давление на продажу. Платформы, такие как Santiment, также предоставляют API и инструменты для помощи разработчикам в интеграции данных настроений в модели прогнозирования.Исследования показаличто включение анализа настроений в социальных сетях может значительно улучшить производительность моделей прогнозирования цен криптовалют, особенно для краткосрочных прогнозов.

Santiment может предоставить данные о настроениях участников рынка по отношению к криптовалютам (Источник: Santiment)
Макроэкономические факторы
Макроэкономические показатели, такие как процентные ставки, уровень инфляции, рост ВВП и уровень безработицы, также влияют на цены криптовалют. Эти факторы влияют на предпочтения инвесторов по риску и потоки капитала. Например, инвесторы могут переносить средства из высокорискованных активов, таких как криптовалюты, в более безопасные альтернативы при росте процентных ставок, что приводит к снижению цен. С другой стороны, когда инфляция растет, инвесторы могут искать активы, сохраняющие стоимость — биткойн иногда рассматривается как защита от инфляции.
Данные о процентных ставках, инфляции, ВВП и безработице обычно можно получить у национальных правительств или международных организаций, таких как Всемирный банк или МВФ. Эти наборы данных обычно доступны в формате CSV или JSON и могут быть получены через библиотеки Python, такие как pandas_datareader.
В следующей таблице кратко изложены общие данные, индикаторы настроений в социальных сетях и макроэкономические факторы, а также то, как они могут повлиять на цены криптовалют:

Как интегрировать данные функции
В общем, этот процесс можно разбить на несколько шагов:
1. Очистка данных и стандартизация
Данные из разных источников могут иметь разные форматы, некоторые могут отсутствовать или быть несогласованными. В таких случаях необходима очистка данных. Например, преобразование всех данных в одинаковый формат даты, заполнение отсутствующих данных и стандартизация данных, чтобы их можно было легче сравнивать.
2. Интеграция данных
После очистки данные из разных источников сливаются на основе дат, создавая полный набор данных, отражающий рыночные условия на каждый день.
3. Построение входной модели
Наконец, эти интегрированные данные преобразуются в формат, который модель может понять. Например, если мы хотим, чтобы модель предсказывала цену сегодня на основе данных за последние 60 дней, мы организуем данные за эти 60 дней в список (или матрицу), чтобы они служили входными данными модели. Модель изучает взаимосвязи в этих данных для прогнозирования будущих тенденций цен.
Модель может использовать более полную информацию для повышения точности прогнозирования через этот процесс инженерии признаков.
Примеры проектов с открытым исходным кодом
На GitHub существует множество популярных проектов по прогнозированию цен на криптовалюты с открытым исходным кодом. В этих проектах используются различные модели машинного обучения и глубокого обучения для прогнозирования тенденций цен различных криптовалют.
Большинство проектов используют популярные фреймворки глубокого обучения, такие как TensorFlowилиKerasдля создания и обучения моделей, изучения шаблонов на основе исторических данных о ценах и прогнозирования будущих движений цен. Весь процесс обычно включает предварительную обработку данных (такую как организацию и стандартизацию исторических данных о ценах), построение модели (определение слоев LSTM и других необходимых слоев), обучение модели (настройка параметров модели через большой набор данных для уменьшения ошибок прогнозирования) и окончательную оценку и визуализацию результатов прогнозирования.
Один из таких проектов, который использует техники глубокого обучения для прогнозирования цен криптовалют, Dat-TG/Криптовалюта-Price-Prediction.
Основная цель этого проекта - использовать модель LSTM для прогнозирования закрывающих цен на биткоин (BTC-USD), эфириум (ETH-USD) и кардано (ADA-USD), чтобы помочь инвесторам лучше понимать тенденции на рынке. Пользователи могут клонировать репозиторий GitHub и запустить приложение локально, следуя предоставленным инструкциям.

Результаты прогнозирования BTC для проекта (Источник: Панель цен криптовалют)
Структура кода этого проекта ясна, с отдельными скриптами и блокнотами Jupyter для получения данных, обучения модели и запуска веб-приложения. На основе структуры каталога проекта и внутреннейкод, процесс построения модели прогнозирования следующий:
- Данные загружаются с Yahoo Finance, затем очищаются и организуются с помощью Pandas, включая такие задачи, как стандартизация формата даты и заполнение отсутствующих значений.
- Обработанные данные генерируют «скользящее окно» — используя прошедшие 60 дней данных для прогнозирования цены на 61-й день.
- Данные затем подаются на вход в модель, построенную с использованием LSTM (долгая краткосрочная память). LSTM эффективно запоминает краткосрочные и долгосрочные изменения цен, что делает его хорошо подходящим для прогнозирования тенденций цен.
- Результаты прогнозирования и фактические цены отображаются с использованием различных графиков через Plotly Dash, с выпадающим меню, позволяющим пользователям выбирать различные криптовалюты или технические индикаторы, обновляя графики в реальном времени.

Структура каталога проекта (Источник: Прогноз цены криптовалюты)
Анализ рисков модели прогнозирования цен криптовалют
Влияние чёрных лебедей на стабильность модели
Событие Черного Лебедя является чрезвычайно редким и непредсказуемым с массовым воздействием. Эти события обычно выходят за рамки ожиданий традиционных прогностических моделей и могут вызвать значительные нарушения на рынке. Типичным примером является Падение Луныв мае 2022 года.
Luna, как проект алгоритмической стейблкоин, полагалась на сложный механизм со своим сестринским токеном LUNA для стабильности. В начале мая 2022 года стейблкоин Luna UST начал открепляться от доллара США, что привело к панической продаже инвесторами. Из-за недостатков алгоритмического механизма коллапс UST привел к резкому увеличению предложения LUNA. В течение нескольких дней цена LUNA упала с почти $80 до практически нуля, уклонившись от сотен миллиардов долларов рыночной стоимости. Это привело к значительным потерям для затронутых инвесторов и вызвало широкие обеспокоенности о системных рисках на рынке криптовалют.
Таким образом, когда происходит событие Черного Лебедя, традиционные модели машинного обучения, обученные на исторических данных, скорее всего никогда не сталкивались с такими экстремальными ситуациями, что приводит к тому, что модели не могут сделать точные прогнозы или даже производят вводящие в заблуждение результаты.
Внутренние риски модели
Помимо событий Черного Лебедя, мы также должны быть внимательны к некоторым врожденным рискам самой модели, которые могут постепенно накапливаться и влиять на точность прогнозирования в повседневном использовании.
(1) Искажение данных и выбросы
Во временных рядах финансовых данных часто наблюдается асимметрия или наличие выбросов. Если не выполняется правильная предобработка данных, процесс обучения модели может быть нарушен шумом, влияющим на точность прогнозирования.
(2) Переупрощенные модели и недостаточная валидация
Некоторые исследования могут слишком сильно полагаться на одну математическую структуру при построении моделей, например, используя только модель ARIMA для улавливания линейных тенденций, игнорируя нелинейные факторы на рынке. Это может привести к слишком упрощенной модели. Кроме того, недостаточная валидация модели может привести к чересчур оптимистичной обратной проверке производительности, но плохим результатам прогнозирования в реальных приложениях (например,переобучениеприводит к отличным результатам на исторических данных, но к значительному отклонению в использовании в реальном мире).
(3) Риск задержки данных API
В живой торговле, если модель полагается на API для получения данных в реальном времени, любая задержка в работе API или невозможность обновления данных вовремя может прямо влиять на работу модели и результаты прогнозирования, что приведет к неудаче в живой торговле.
Меры по повышению стабильности модели прогнозирования
Перед рисками, упомянутыми выше, необходимо предпринять соответствующие меры для улучшения стабильности модели. Особенно важны следующие стратегии:
(1) Разнообразные источники данных и предварительная обработка данных
Комбинирование нескольких источников данных (таких как исторические цены, объем торгов, данные социального настроения и т. д.) может компенсировать недостатки одной модели, в то время как следует проводить тщательную очистку, трансформацию и разделение данных. Этот подход улучшает обобщающую способность модели и снижает риски, связанные с искажением данных и выбросами.
(2) Выбор соответствующих метрик оценки модели
В процессе построения модели важно выбрать соответствующие метрики оценки на основе характеристик данных (таких как MAPE, RMSE, AIC, BIC и т. д.) для оценки производительности модели и комплексного избегания переобучения. Регулярная перекрестная проверка и прогнозирование с прокруткой также являются важными шагами для улучшения устойчивости модели.
(3) Проверка модели и итерация
После того как модель установлена, её следует тщательно валидировать с использованием анализа остатков и механизмов обнаружения аномалий. Стратегия прогнозирования должна непрерывно корректироваться на основе изменений на рынке. Например, внедрение контекстно-ориентированного обучения для корректировки параметров модели с учётом текущих рыночных условий динамически является одним из подходов. Кроме того, комбинирование традиционных моделей с моделями глубокого обучения для создания гибридной модели является эффективным методом для улучшения точности и стабильности прогнозирования.
Внимание к рискам соответствия
Наконец, помимо технических рисков, необходимо учитывать риски конфиденциальности данных и соответствия при использовании нетрадиционных источников данных, таких как данные о настроениях. Например, Комиссия по ценным бумагам и биржам США (SECSEC) имеет строгие требования к проверке сбора и использования данных о настроениях, чтобы предотвратить правовые риски, связанные с проблемами конфиденциальности.
Это означает, что во время процесса сбора данных лично идентифицируемая информация (такая как имена пользователей, личные данные и т. д.) должна быть анонимизирована. Это направлено на предотвращение раскрытия личной конфиденциальности, а также на избежание неправильного использования данных. Кроме того, важно обеспечить легитимность источников собранных данных и исключить получение их неправомерными способами (например, через несанкционированный веб-скрапинг). Также необходимо публично раскрывать методы сбора и использования данных, что позволит инвесторам и регулирующим органам понять, как данные обрабатываются и применяются. Эта прозрачность помогает предотвратить использование данных для манипулирования рыночным настроением.
Заключение и перспективы развития
В заключение, модели прогнозирования цен криптовалют на основе машинного обучения показывают большой потенциал в решении волатильности и сложности рынка. Интеграция стратегий управления рисками и постоянное исследование новых архитектур моделей и методов интеграции данных будут важными направлениями для будущего развития прогнозирования цен криптовалют. С развитием технологий машинного обучения, мы верим, что появятся более точные и стабильные модели прогнозирования цен криптовалют, обеспечивающие инвесторов более надежной поддержкой в принятии решений.