Thị trường tiền điện tử nổi tiếng với sự biến động cực kỳ lớn, tạo cơ hội đáng kể cho các nhà đầu tư, nhưng cũng mang lại rủi ro đáng kể. Dự đoán giá chính xác là rất quan trọng để đưa ra quyết định đầu tư có hiểu biết. Tuy nhiên, các phương pháp phân tích tài chính truyền thống thường gặp khó khăn trong việc xử lý sự phức tạp và sự thay đổi nhanh chóng của thị trường tiền điện tử. Trong những năm gần đây, sự tiến bộ của học máy đã cung cấp các công cụ mạnh mẽ cho việc dự báo chuỗi thời gian tài chính, đặc biệt là trong dự đoán giá tiền điện tử.
Các thuật toán học máy có thể học từ lượng lớn dữ liệu lịch sử về giá cả và các thông tin liên quan khác, nhận diện các mẫu khó nhận biết đối với con người. Trong số nhiều mô hình học máy khác nhau, Mạng Nơ-ron Hồi quy (RNNs) và các biến thể của chúng, như Long Short-Term Memory (LSTM) và các mô hình Transformer, đã thu hút sự chú ý rộng rãi với khả năng xuất sắc của chúng trong việc xử lý dữ liệu tuần tự, cho thấy tiềm năng tăng lên trong việc dự báo giá tiền điện tử. Bài viết này cung cấp một phân tích sâu sắc về các mô hình dựa trên học máy cho việc dự đoán giá tiền điện tử, tập trung vào việc so sánh ứng dụng của LSTM và Transformer. Nó cũng khám phá cách tích hợp các nguồn dữ liệu đa dạng có thể cải thiện hiệu suất mô hình và xem xét tác động của các sự kiện thiên nga đen đối với sự ổn định của mô hình.
Ứng dụng Machine Learning trong Dự đoán Giá Tiền điện tử
Ý tưởng cơ bản của việc học máy là để cho phép máy tính học từ các bộ dữ liệu lớn và đưa ra dự đoán dựa trên các mẫu đã học. Các thuật toán này phân tích các thay đổi giá cả lịch sử, khối lượng giao dịch và dữ liệu liên quan khác để phát hiện ra các xu hướng và mẫu ẩn. Các phương pháp phổ biến bao gồm phân tích hồi quy, cây quyết định và mạng nơ-ron, tất cả đã được sử dụng rộng rãi trong việc xây dựng các mô hình dự đoán giá tiền điện tử.
Hầu hết các nghiên cứu đều dựa vào các phương pháp thống kê truyền thống trong giai đoạn đầu của việc dự báo giá tiền điện tử. Ví dụ, vào khoảng năm 2017, trước khi học sâu trở nên phổ biến, nhiều nghiên cứu đã sử dụng các mô hình ARIMA để dự đoán xu hướng giá của các loại tiền điện tử như Bitcoin. Một nghiên cứu đại diện của Dong, Li và Gong (2017) đã sử dụng mô hình ARIMA để phân tích sự biến động của Bitcoin, thể hiện tính ổn định và đáng tin cậy của các mô hình truyền thống trong việc nắm bắt các xu hướng tuyến tính.
Với sự tiến bộ về công nghệ, các phương pháp học sâu bắt đầu cho thấy những kết quả đột phá trong việc dự báo chuỗi thời gian tài chính vào năm 2020. Đặc biệt, mạng Long Short-Term Memory (LSTM) trở nên phổ biến nhờ khả năng nắm bắt các phụ thuộc dài hạn trong dữ liệu chuỗi thời gian. học tậpbởi Patel et al. (2019) đã chứng minh những ưu điểm của LSTM trong dự đoán giá Bitcoin, đánh dấu một bước tiến quan trọng vào thời điểm đó.
Đến năm 2023, các mô hình Transformer - với cơ chế tự chú ý độc đáo của họ có khả năng capture mối quan hệ trên toàn bộ chuỗi dữ liệu cùng một lúc - ngày càng được áp dụng nhiều trong dự báo chuỗi thời gian tài chính. Ví dụ, năm 2023 của Zhao và cộng sự.học tập“Chú ý! Mô hình Transformer với Tâm trạng về Dự đoán Giá Tiền điện tử” đã tích hợp thành công các mô hình Transformer với dữ liệu tâm trạng trên mạng xã hội, cải thiện đáng kể độ chính xác của dự đoán xu hướng giá tiền điện tử, đánh dấu một cột mốc quan trọng trong lĩnh vực này.

Các bước đột phá trong Công nghệ Dự đoán Tiền điện tử (Nguồn: Gate Learn Creator John)
Trong số nhiều mô hình học máy, các mô hình học sâu - đặc biệt là Mạng Nơ-ron Hồi quy (RNNs) và các phiên bản tiên tiến của chúng, LSTM và Transformer - đã chứng minh được những lợi thế đáng kể trong việc xử lý dữ liệu chuỗi thời gian. RNNs được thiết kế đặc biệt để xử lý dữ liệu tuần tự bằng cách truyền thông tin từ các bước trước sang các bước sau, hiệu quả trong việc nắm bắt sự phụ thuộc qua các điểm thời gian. Tuy nhiên, RNNs truyền thống gặp khó khăn với vấn đề “gradient biến mất” khi xử lý các chuỗi dài, gây ra việc mất dần thông tin cũ nhưng quan trọng. Để giải quyết vấn đề này, LSTM giới thiệu các ô nhớ và cơ chế cổng trên cơ sở của RNNs, cho phép giữ lại thông tin quan trọng lâu dài và mô hình hóa tốt hơn các phụ thuộc dài hạn. Khi dữ liệu tài chính, như giá tiền điện tử lịch sử, thể hiện đặc điểm thời gian mạnh mẽ, các mô hình LSTM đặc biệt phù hợp để dự đoán xu hướng như vậy.
Trong khi đó, các mô hình Transformer ban đầu được phát triển cho xử lý ngôn ngữ̛. Mẹcanism tự chú ý cho phép mô hình xem xét mối quan hệ trên toàn bộ dãy dữ liệu cùng một lúc, chứ không xử lý chúng bước đến bước. Kiến trúc này đem đến tiềm nàng tiềm năng to lớn cho các mô hình Transformer trong việc dự đoán dãy dữ liệu tài chính với các phụ thuộc thời gian phức tạp.
So sánh các mô hình dự đoán
Các mô hình truyền thống như ARIMA thường được sử dụng như cơ sở so sánh cùng với các mô hình học sâu trong dự đoán giá tiền điện tử. ARIMA được thiết kế để bắt các xu hướng tuyến tính và các thay đổi tỷ lệ nhất quán trong dữ liệu, hoạt động tốt trong nhiều nhiệm vụ dự báo. Tuy nhiên, do tính biến động cao và phức tạp của giá tiền điện tử, các giả thiết tuyến tính của ARIMA thường không đạt được kết quả mong muốn.Các nghiên cứu đã chỉ rarằng các mô hình học sâu thông thường cung cấp dự đoán chính xác hơn trong các thị trường phi tuyến và biến động cao.
Trong số các phương pháp học sâu, nghiên cứu so sánh mô hình LSTM và Transformer trong dự đoán giá Bitcoin đã phát hiện ra rằng LSTM hoạt động tốt hơn khi ghi lại các chi tiết tinh tế của các biến động giá ngắn hạn. Ưu điểm này chủ yếu đến từ cơ chế bộ nhớ của LSTM, giúp nó mô hình hoá các phụ thuộc ngắn hạn một cách hiệu quả và ổn định hơn. Trong khi LSTM có thể vượt trội trong việc dự báo chính xác ngắn hạn, các mô hình Transformer vẫn rất cạnh tranh. Khi được tăng cường bằng dữ liệu ngữ cảnh bổ sung—như phân tích cảm xúc từ Twitter—Transformers có thể cung cấp một sự hiểu biết thị trường rộng hơn, cải thiện đáng kể hiệu suất dự đoán.
Hơn nữa, một số nghiên cứu đã khám phá các mô hình kết hợp kỹ thuật học sâu với phương pháp thống kê truyền thống, như LSTM-ARIMA. Những mô hình kết hợp này nhằm bắt lấy cả mô hình tuyến tính và phi tuyến tính trong dữ liệu, từ đó nâng cao độ chính xác và tính ổn định của mô hình dự đoán.
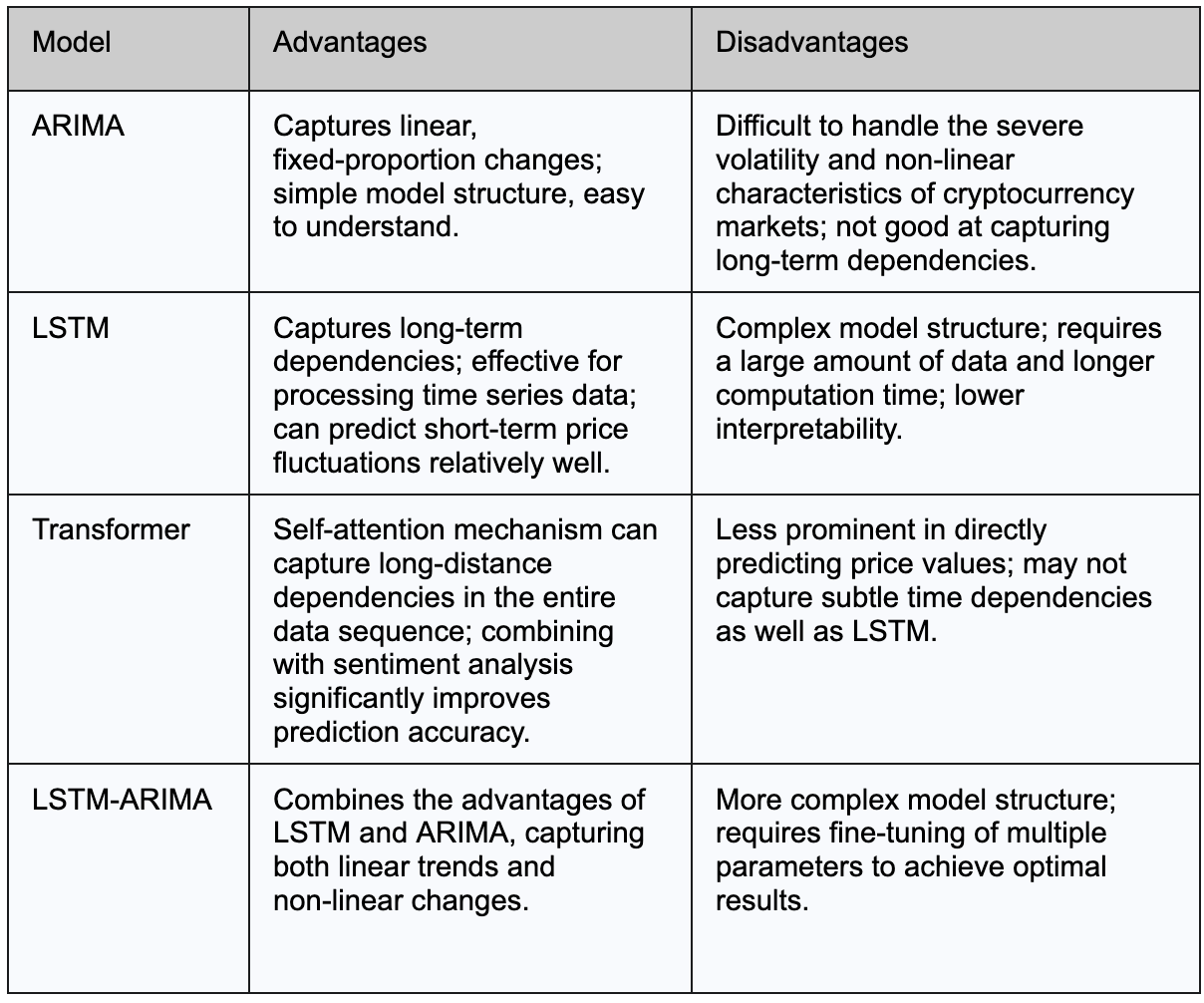
Bảng dưới đây tóm tắt những ưu điểm và nhược điểm chính của các mô hình ARIMA, LSTM và Transformer trong dự đoán giá Bitcoin:
Nâng cao độ chính xác dự đoán với kỹ thuật kỹ thuật đặc trưng
Khi dự báo giá tiền điện tử, chúng tôi không chỉ dựa vào dữ liệu giá lịch sử mà còn tích hợp thêm thông tin giá trị khác để giúp các mô hình dự báo chính xác hơn. Quá trình này được gọi là kỹ thuật kỹ thuật đặc trưng, bao gồm việc tổ chức và xây dựng các "đặc trưng" dữ liệu nhằm tăng cường hiệu suất dự báo.
Các Nguồn Dữ Liệu Tính Năng Phổ Biến
Dữ liệu trên chuỗi
Dữ liệu trên chuỗiđề cập đến tất cả thông tin giao dịch và hoạt động được ghi lại trên chuỗi khối, bao gồm khối lượng giao dịch, số địa chỉ hoạt động,độ khó khai thác, và tốc độ bămNhững chỉ số này phản ánh trực tiếp động lực cung cầu thị trường và hoạt động mạng tổng thể, khiến chúng trở nên rất quý giá đối với dự báo giá. Ví dụ, một đợt tăng đột ngột đáng kể trong khối lượng giao dịch có thể báo hiệu một sự thay đổi trong tâm lý thị trường, trong khi một tăng về địa chỉ hoạt động có thể chỉ ra sự áp dụng rộng rãi hơn, tiềm năng đẩy giá lên.
Dữ liệu như vậy thường được truy cập thông qua các API khám phá blockchain hoặc các nhà cung cấp dữ liệu chuyên biệt như Glassnode và Coin Metrics. Bạn có thể sử dụng thư viện requests của Python để gọi các API hoặc tải trực tiếp các tệp CSV để phân tích.
Chỉ số tâm lý mạng xã hội
Các nền tảng như SantimentPhân tích nội dung văn bản từ các nguồn như Twitter và Reddit để đánh giá tâm trạng của các bên tham gia thị trường đối với tiền điện tử. Họ tiếp tục áp dụng các kỹ thuật xử lý ngôn ngữ tự nhiên (NLP) như phân tích cảm xúc để chuyển đổi văn bản này thành các chỉ số cảm xúc. Các chỉ số này phản ánh ý kiến và kỳ vọng của nhà đầu tư, cung cấp thông tin quý giá cho việc dự đoán giá. Ví dụ, tâm trạng tích cực chiếm ưu thế trên các phương tiện truyền thông xã hội có thể thu hút nhiều nhà đầu tư hơn và đẩy giá lên, trong khi tâm trạng tiêu cực có thể kích hoạt áp lực bán ra. Các nền tảng như Santiment cũng cung cấp API và công cụ để giúp các nhà phát triển tích hợp dữ liệu cảm xúc vào các mô hình dự đoán.Nghiên cứu đã chỉ rarằng việc tích hợp phân tích tâm trạng trên mạng xã hội có thể cải thiện đáng kể hiệu suất của các mô hình dự đoán giá tiền điện tử, đặc biệt là đối với dự báo ngắn hạn.

Santiment có thể cung cấp dữ liệu tâm trạng về quan điểm của các nhà thị trường về tiền điện tử (Nguồn: Santiment)
Yếu tố kinh tế vĩ mô
Các chỉ số kinh tế lớn như lãi suất, tỷ lệ lạm phát, tăng trưởng GDP và tỷ lệ thất nghiệp cũng ảnh hưởng đến giá của tiền điện tử. Những yếu tố này ảnh hưởng đến sở thích rủi ro của nhà đầu tư và dòng vốn. Ví dụ, nhà đầu tư có thể chuyển vốn từ tài sản có rủi ro cao như tiền điện tử sang các lựa chọn an toàn khi lãi suất tăng, dẫn đến sụt giảm giá. Ngược lại, khi lạm phát tăng, nhà đầu tư có thể tìm kiếm các tài sản bảo tồn giá trị—Bitcoin đôi khi được coi là một cách bảo vệ chống lại lạm phát.
Dữ liệu về lãi suất, lạm phát, tăng trưởng GDP và thất nghiệp thường có thể được lấy từ các chính phủ quốc gia hoặc các tổ chức quốc tế như Ngân hàng Thế giới hoặc IMF. Các bộ dữ liệu này thường có sẵn ở định dạng CSV hoặc JSON và có thể được truy cập thông qua các thư viện Python như pandas_datareader.
Bảng dưới đây tóm tắt dữ liệu trên chuỗi thông thường được sử dụng, chỉ số tâm lý trên mạng xã hội và các yếu tố kinh tế chung, cùng với cách chúng có thể ảnh hưởng đến giá của tiền điện tử:

Cách tích hợp dữ liệu tính năng
Nhìn chung, quá trình này có thể được chia nhỏ thành một số bước:
1. Dọn dẹp dữ liệu và chuẩn hóa
Dữ liệu từ các nguồn khác nhau có thể có định dạng khác nhau, một số có thể thiếu hoặc không nhất quán. Trong những trường hợp như vậy, việc làm sạch dữ liệu là cần thiết. Ví dụ, chuyển tất cả dữ liệu thành cùng một định dạng ngày, điền vào dữ liệu thiếu, và chuẩn hóa dữ liệu để có thể so sánh dễ dàng hơn.
2. Data Integration
Sau khi dọn dẹp, dữ liệu từ các nguồn khác nhau được hợp nhất dựa trên ngày, tạo thành một bộ dữ liệu hoàn chỉnh thể hiện điều kiện thị trường cho mỗi ngày.
3. Xây dựng Đầu vào Mô hình
Cuối cùng, dữ liệu tích hợp này được chuyển đổi thành định dạng mà mô hình có thể hiểu được. Ví dụ, nếu chúng ta muốn mô hình dự đoán giá hôm nay dựa trên dữ liệu từ 60 ngày qua, chúng ta sẽ tổ chức dữ liệu từ những 60 ngày đó thành một danh sách (hoặc ma trận) để phục vụ làm đầu vào của mô hình. Mô hình học các mối quan hệ trong dữ liệu này để dự đoán xu hướng giá trong tương lai.
Mô hình có thể tận dụng thông tin toàn diện hơn để cải thiện độ chính xác dự đoán thông qua quá trình kỹ thuật này.
Ví dụ Dự án Mã Nguồn Mở
Trên GitHub có rất nhiều dự án dự đoán giá tiền điện tử nguồn mở phổ biến. Những dự án này sử dụng các mô hình học máy và học sâu khác nhau để dự đoán xu hướng giá của các loại tiền điện tử khác nhau.
Hầu hết các dự án sử dụng các framework học sâu phổ biến như TensorFlowhoặcKerasđể xây dựng và huấn luyện các mô hình, học các mẫu từ dữ liệu giá lịch sử và dự đoán các biến động giá trong tương lai. Toàn bộ quy trình thường bao gồm tiền xử lý dữ liệu (như tổ chức và chuẩn hóa dữ liệu giá lịch sử), xây dựng mô hình (xác định các lớp LSTM và các lớp cần thiết khác), huấn luyện mô hình (điều chỉnh các tham số mô hình thông qua một bộ dữ liệu lớn để giảm lỗi dự đoán) và đánh giá cuối cùng và trực quan hóa kết quả dự đoán.
Một dự án như vậy sử dụng các kỹ thuật học sâu để dự đoán giá tiền điện tử là Dat-TG/Dự-đoán-Giá-Tiền-điện-tử.
Mục tiêu chính của dự án này là sử dụng mô hình LSTM để dự đoán giá đóng cửa của Bitcoin (BTC-USD), Ethereum (ETH-USD) và Cardano (ADA-USD) để giúp nhà đầu tư hiểu rõ hơn về xu hướng thị trường. Người dùng có thể sao chép kho lưu trữ GitHub và chạy ứng dụng trên máy cục bộ theo hướng dẫn được cung cấp.

Kết quả dự đoán BTC cho Dự án (Nguồn: Bảng giá Tiền điện tử)
Cấu trúc mã của dự án này rõ ràng, với các kịch bản riêng và Jupyter Notebooks để lấy dữ liệu, huấn luyện mô hình, và chạy ứng dụng web. Dựa trên cấu trúc thư mục dự án và bên trong mã, quá trình xây dựng mô hình dự đoán như sau:
- Dữ liệu được tải về từ Yahoo Finance, sau đó được làm sạch và tổ chức bằng cách sử dụng Pandas, bao gồm các nhiệm vụ như chuẩn hóa định dạng ngày tháng và điền vào các giá trị thiếu.
- Dữ liệu đã được xử lý tạo ra một “cửa sổ trượt” — sử dụng dữ liệu trong 60 ngày qua để dự đoán giá cho ngày thứ 61.
- Dữ liệu sau đó được đưa vào một mô hình được xây dựng bằng LSTM (Long Short-Term Memory). LSTM hiệu quả trong việc ghi nhớ các thay đổi giá ngắn hạn và dài hạn, làm cho nó phù hợp để dự đoán xu hướng giá.
- Kết quả dự đoán và giá thực tế được hiển thị bằng các biểu đồ khác nhau thông qua Plotly Dash, với một menu thả xuống cho phép người dùng chọn các loại tiền điện tử hoặc chỉ số kỹ thuật khác nhau, cập nhật biểu đồ trong thời gian thực.

Cấu trúc Thư mục Dự án (Nguồn: Tiền điện tử-Giá-Dự đoán)
Phân tích rủi ro mô hình dự đoán giá tiền điện tử
Tác động của Sự Kiện Black Swan đối với Sự Ổn Định của Mô Hình
Sự kiện Black Swan rất hiếm và không thể dự đoán với tác động lớn. Những sự kiện này thường nằm ngoài dự đoán của các mô hình dự đoán thông thường và có thể gây ra sự đột ngột đáng kể trên thị trường. Một ví dụ điển hình là Sự sụp đổ của Lunavào tháng 5 năm 2022.
Luna, dựa vào một cơ chế phức tạp với token chị em LUNA của mình để ổn định, như một dự án stablecoin theo thuật toán. Vào đầu tháng 5 năm 2022, stablecoin UST của Luna bắt đầu rút lui khỏi đô la Mỹ, dẫn đến việc bán hoảng loạn của các nhà đầu tư. Do lỗ hổng của cơ chế thuật toán, sự sụp đổ của UST đã khiến nguồn cung LUNA tăng vọt. Trong vài ngày, giá của LUNA lao dốc từ gần 80 đô la xuống gần như không, trốn thoát hàng trăm tỷ đô la giá trị thị trường. Điều này đã gây ra những tổn thất đáng kể cho các nhà đầu tư liên quan và gây ra lo ngại rộng rãi về các rủi ro hệ thống trong thị trường tiền điện tử.
Do đó, khi một sự kiện Black Swan xảy ra, các mô hình học máy truyền thống được huấn luyện trên dữ liệu lịch sử có thể chưa bao giờ gặp phải những tình huống cực đoan như vậy, dẫn đến việc mô hình thất bại trong việc đưa ra dự đoán chính xác hoặc thậm chí tạo ra kết quả sai lệch.
Rủi ro bẩm sinh của mô hình
Ngoài các sự kiện Black Swan, chúng ta cũng phải nhận thức về một số rủi ro bẩm sinh trong mô hình chính nó, có thể dần dần tích tụ và ảnh hưởng đến độ chính xác của dự đoán trong việc sử dụng hàng ngày.
(1) Dữ liệu lệch và điểm ngoại lai
Trong chuỗi thời gian tài chính, dữ liệu thường có sự lệch hoặc chứa các giá trị ngoại lệ. Nếu không thực hiện xử lý dữ liệu đúng cách, quá trình huấn luyện mô hình có thể bị ảnh hưởng bởi nhiễu, làm giảm độ chính xác của dự đoán.
(2) Mô hình quá đơn giản và Thiếu xác thực đầy đủ
Một số nghiên cứu có thể phụ thuộc quá nhiều vào một cấu trúc toán học duy nhất khi xây dựng các mô hình, chẳng hạn như chỉ sử dụng mô hình ARIMA để bắt kịp xu hướng tuyến tính trong khi bỏ qua các yếu tố phi tuyến tính trên thị trường. Điều này có thể dẫn đến sự đơn giản hoá quá mức của mô hình. Ngoài ra, việc xác thực mô hình không đủ có thể dẫn đến hiệu suất backtesting quá lạc quan, nhưng kết quả dự đoán kém trong các ứng dụng thực tế (ví dụ,Overfittingdẫn đến hiệu suất xuất sắc trên dữ liệu lịch sử nhưng chênh lệch đáng kể trong việc sử dụng thực tế).
(3) Rủi ro trễ dữ liệu API
Trong giao dịch trực tiếp, nếu mô hình phụ thuộc vào API để có dữ liệu thời gian thực, bất kỳ sự trễ trên API hoặc việc cập nhật dữ liệu không kịp thời đều có thể ảnh hưởng trực tiếp đến hoạt động của mô hình và kết quả dự đoán, dẫn đến thất bại trong giao dịch trực tiếp.
Biện pháp để Nâng cao Ổn định Mô hình Dự đoán
Đối diện với những rủi ro được đề cập ở trên, cần áp dụng các biện pháp tương ứng để cải thiện sự ổn định của mô hình. Các chiến lược sau đây đặc biệt quan trọng:
(1) Nguồn dữ liệu đa dạng và tiền xử lý dữ liệu
Kết hợp nhiều nguồn dữ liệu (như giá lịch sử, khối lượng giao dịch, dữ liệu tâm lý xã hội, v.v.) có thể bù đắp cho nhược điểm của một mô hình duy nhất, trong khi việc làm sạch dữ liệu, biến đổi và chia nhỏ nghiêm ngặt cũng nên được thực hiện. Phương pháp này nâng cao khả năng tổng quát của mô hình và giảm thiểu các rủi ro do sự méo mó và giá trị ngoại lệ của dữ liệu.
(2) Chọn các chỉ số đánh giá mô hình phù hợp
Trong quá trình xây dựng mô hình, việc lựa chọn các chỉ số đánh giá phù hợp dựa trên các đặc tính dữ liệu (như MAPE, RMSE, AIC, BIC, v.v.) để đánh giá hiệu suất của mô hình và tránh tình trạng quá khớp là rất quan trọng. Việc thực hiện cross-validation định kỳ và dự báo lăn là những bước quan trọng để cải thiện tính mạnh mẽ của mô hình.
(3) Xác thực mô hình và lặp lại
Khi mô hình đã được thiết lập, nó nên trải qua việc xác thực kỹ lưỡng bằng cách sử dụng phân tích dư và cơ chế phát hiện bất thường. Chiến lược dự đoán nên được điều chỉnh liên tục dựa trên sự thay đổi của thị trường. Ví dụ, việc áp dụng học có bối cảnh để điều chỉnh các tham số mô hình theo điều kiện thị trường hiện tại một cách linh hoạt là một phương pháp. Ngoài ra, kết hợp các mô hình truyền thống với các mô hình học sâu để tạo thành một mô hình lai là một phương pháp hiệu quả để cải thiện độ chính xác và ổn định trong dự đoán.
Chú ý đến các rủi ro tuân thủ
Cuối cùng, ngoài những rủi ro về mặt kỹ thuật, cần phải xem xét các rủi ro về quyền riêng tư dữ liệu và tuân thủ khi sử dụng các nguồn dữ liệu phi truyền thống như dữ liệu tâm trạng. Ví dụ, Ủy ban Chứng khoán và Giao dịch Hoa Kỳ (SEC)SEC) có yêu cầu kiểm định nghiêm ngặt liên quan đến việc thu thập và sử dụng dữ liệu tâm trạng để ngăn ngừa rủi ro pháp lý phát sinh từ các vấn đề về quyền riêng tư.
Điều này có nghĩa là trong quá trình thu thập dữ liệu, thông tin cá nhân có thể xác định được (như tên người dùng, chi tiết cá nhân, v.v.) phải được ẩn danh. Điều này nhằm mục đích ngăn chặn thông tin riêng tư cá nhân bị tiết lộ trong khi cũng tránh việc sử dụng dữ liệu một cách không đúng đắn. Ngoài ra, quan trọng phải đảm bảo rằng các nguồn dữ liệu thu thập là hợp pháp và không được thu thập thông qua các phương tiện không đúng đắn (như web scraping trái phép). Việc tiết lộ công khai phương pháp thu thập và sử dụng dữ liệu cũng rất quan trọng, giúp các nhà đầu tư và cơ quan quản lý hiểu cách dữ liệu được xử lý và áp dụng. Sự minh bạch này giúp ngăn chặn dữ liệu bị sử dụng để thao túng tâm lý thị trường.
Kết luận và Triển vọng trong Tương lai
Kết luận, các mô hình dự đoán giá tiền điện tử dựa trên học máy cho thấy tiềm năng lớn trong việc giải quyết sự biến động và phức tạp của thị trường. Việc tích hợp các chiến lược quản lý rủi ro và liên tục khám phá các kiến trúc mô hình mới và phương pháp tích hợp dữ liệu sẽ là hướng phát triển quan trọng cho dự đoán giá tiền điện tử trong tương lai. Với sự tiến bộ của công nghệ học máy, chúng tôi tin rằng sẽ có nhiều mô hình dự đoán giá tiền điện tử chính xác và ổn định hơn xuất hiện, cung cấp hỗ trợ quyết định mạnh mẽ hơn cho nhà đầu tư.







