
ระบบ AI สำหรับความทรงจำ MemPalace ที่ Milla Jovovich ร่วมพัฒนา อ้างว่าได้คะแนนเต็มจากการทดสอบแล้วกลับมาเป็นกระแสไวรัล แต่กลับถูกชุมชนสับว่าอาจมีการโกงในการทดสอบและทำให้ข้อมูลคลาดเคลื่อน จากการทดสอบจริงพบว่าผลลัพธ์ถูกคุยโวเกินจริงและมีข้อผิดพลาดจำนวนมาก ทีมงานยอมรับข้อบกพร่องแล้วและกำลังเร่งแก้ไขอยู่
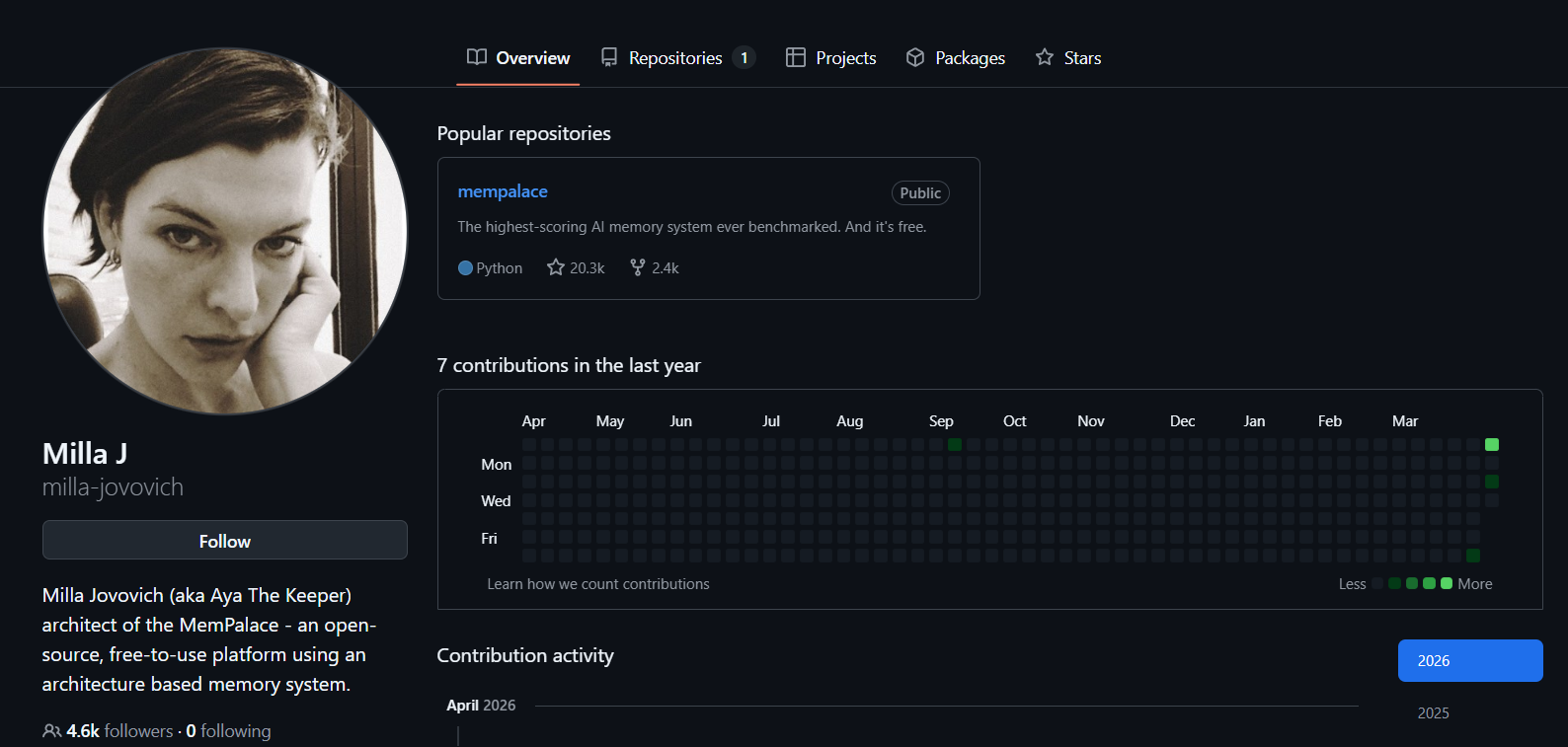
Milla Jovovich สร้าง AI Memory Palace ดึงดูดความสนใจจากภายนอก
เมื่อวานนี้ (4/7) ในแวดวง AI มีข่าวใหญ่ว่า นักแสดงสาวฮอลลีวูด Milla·Jovovich ซึ่งเป็นที่รู้จักจาก Resident Evil และ The Fifth Element ร่วมกับ Ben Sigman นักพัฒนา โดยใช้ Claude Code เพื่อพัฒนา “MemPalace” ซึ่งเป็นระบบความทรงจำ AI แบบโอเพนซอร์ส
ในชั่วขณะหนึ่ง มีการแพร่กระจายคำกล่าวอ้างว่า “ซุปเปอร์สตาร์ฮอลลีวูดข้ามสายงานทำโปรเจกต์ที่ได้คะแนนเต็ม” MemPalace จนถึงตอนนี้บน GitHub ก็ได้รับมากกว่า 20k สตาร์ แต่ไม่นานก็เกิดคำถามจากชุมชนผู้พัฒนาว่า: จริงหรือที่มีของ หรือเป็นการโปรโมตเกินจริง?
มาดูแรงจูงใจที่ทำให้ MemPalace ถือกำเนิดก่อน โดยเอกสารทางการระบุว่าเป็นการพยายามแก้ปัญหาที่เนื้อหาการสนทนา กระบวนการตัดสินใจ และการอภิปรายโครงสร้างของระบบ AI โดยผู้ใช้กับ AI โดยทั่วไปจะหายไปหลังจบเซสชันการทำงาน ทำให้ความพยายามหลายเดือนต้องสูญเปล่า
เพื่อแก้ปัญหานี้ MemPalace ใช้โครงสร้างเชิงพื้นที่เพื่อจัดเก็บความทรงจำ โดยจัดหมวดหมู่อย่างชัดเจนเป็นโซนปีกที่เป็นตัวแทนบุคคลหรือโปรเจกต์ และโครงสร้างในระดับต่าง ๆ เช่น โถงทางเดิน ห้อง และลิ้นชัก เพื่อเก็บต้นฉบับของบทสนทนาไว้สำหรับการค้นคืนเชิงความหมายในภายหลัง
ทีมพัฒนาระบุว่า MemPalace ได้คะแนนสมบูรณ์ 100% ในเกณฑ์การประเมินความทรงจำระยะยาว LongMemEval และยังได้ความแม่นยำ 96.6% โดยที่ไม่เรียกใช้ API ภายนอกใด ๆ อีกด้วย อีกทั้งสามารถทำงานได้ทั้งหมดบนเครื่องท้องถิ่น ไม่จำเป็นต้องสมัครบริการคลาวด์ และมาพร้อมระบบภาษาถิ่น AAAK ที่อ้างว่าสามารถทำการบีบอัดแบบไม่สูญเสียได้ถึง 30 เท่า
ภาพที่มา:GitHub Milla Jovovich ดาราภาพยนตร์สหรัฐฯ สร้าง AI Memory Palace ดึงดูดความสนใจจากภายนอก
คู่แข่งและชุมชนตั้งข้อสงสัยพร้อมกัน วิธีทดสอบและการโปรโมตมีจุดบกพร่อง
อย่างไรก็ตาม ผลการทดสอบที่อ้างว่า LongMemEval ได้คะแนนเต็ม ก็ไม่นานก็ถูกตั้งคำถามจากคู่แข่ง
PenfieldLabs ซึ่งเป็นอีกผู้พัฒนาที่ทำระบบความทรงจำ AI ระบุว่า MemPalace อ้างว่าได้คะแนนเต็มในชุดข้อมูล LoCoMo ซึ่งในเชิงคณิตศาสตร์เป็นไปไม่ได้ เพราะคำตอบมาตรฐานของชุดข้อมูลนั้นมีข้อผิดพลาดอยู่ 99 รายการแล้ว
PenfieldLabs วิเคราะห์พบว่า ผลงาน 100% ของ MemPalace มาจากการตั้งจำนวนการค้นคืนไว้ที่ 50 ครั้ง แต่จำนวนขั้นสูงสุดในบทสนทนาของชุดทดสอบมีเพียง 32 ครั้งเท่านั้น ซึ่งหมายความว่าระบบหลีกเลี่ยงขั้นตอนการค้นคืนโดยตรง แล้วส่งข้อมูลทั้งหมดให้โมเดล AI อ่าน
สำหรับผล 100% ใน LongMemEval ทีมพัฒนาถูกพบว่าแก้ไขเฉพาะปัญหาเฉพาะ 3 รายการที่มีแนวโน้มจะพลาดในการพัฒนา โดยเขียนโค้ดสำหรับการแก้ไขโดยเฉพาะ มีความน่าสงสัยว่าเป็นการโกงเพื่อทำให้ชุดทดสอบผ่าน

ภาพที่มา:Reddit PenfieldLabs ระบุว่า MemPalace อ้างว่าได้คะแนนเต็มในชุดข้อมูล LoCoMo ซึ่งในเชิงคณิตศาสตร์เป็นไปไม่ได้
ผู้ใช้ GitHub ทดสอบจริง พบส่วนประกอบที่ทำให้เข้าใจผิดในชุดการวัดผล
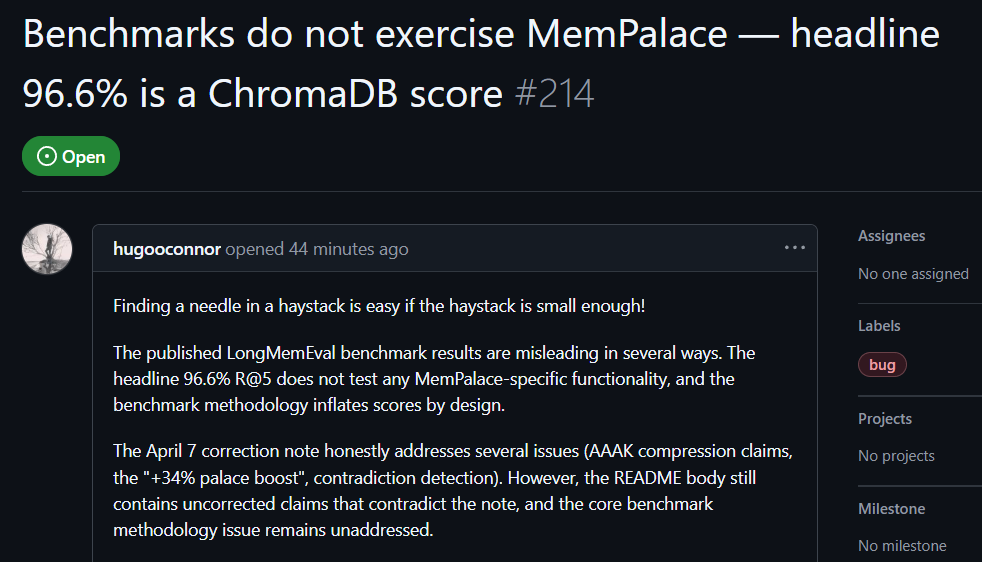
ผู้ใช้ GitHub hugooconnor แสดงความคิดเห็นหลังทดสอบจริงว่า MemPalace อ้างว่ามีความแม่นยำในการค้นคืนสูงถึง 96.6% แต่ในความเป็นจริงไม่ได้ใช้สถาปัตยกรรม Memory Palace ตามที่โฆษณาไว้เลย hugooconnor ระบุว่าการทดสอบของพวกเขาเป็นเพียงการเรียกใช้ฟังก์ชันเริ่มต้นของฐานข้อมูลระดับล่าง ChromaDB เท่านั้น โดยไม่ได้เกี่ยวข้องกับตรรกะการจัดหมวดหมู่ที่โปรเจกต์เน้นย้ำ เช่น โซนปีก ห้อง หรือ ลิ้นชัก
หลังจากทดสอบแล้ว hugooconnor พบว่าเมื่อเปิดใช้งานตรรกะการจัดหมวดหมู่เฉพาะของ Memory Palace จริง ๆ ผลคะแนนการค้นคืนกลับลดลง ยกตัวอย่างในโหมดห้อง ความแม่นยำลดลงเหลือ 89.4% และเมื่อเปิดใช้งานเทคโนโลยีการบีบอัด AAAK ความแม่นยำยิ่งตกลงไปที่ 84.2% ทั้งสองกรณีต่ำกว่าประสิทธิภาพของฐานข้อมูลค่าเริ่มต้น
hugooconnor ยังวิจารณ์วิธีการทดสอบ โดยสภาพแวดล้อมการทดสอบของ MemPalace ตั้งใจลดขอบเขตการค้นคืนของแต่ละปัญหาให้แคบลงเหลือประมาณ 50 ช่วงของบทสนทนา การค้นหาคำตอบในคลังข้อมูลตัวอย่างที่เล็กมากจึงง่ายเกินไป
หากขยายขอบเขตไปเป็นกว่า 19,000 ช่วงบทสนทนาในสถานการณ์จริง ความแม่นยำของการค้นหาด้วยคำหลักแบบดั้งเดิมจะดิ่งลงเหลือ 30% แสดงให้เห็นว่าวิธีทดสอบปัจจุบันของ MemPalace ปิดบังปัญหาความยากจริงของการค้นหา
ภาพที่มา:GitHub ผู้ใช้ GitHub ทดสอบจริง พบส่วนประกอบที่ทำให้เข้าใจผิดในชุดการวัดผลของ MemPalace
ในขณะเดียวกัน แม้ทีมพัฒนาจะเผยแพร่คำชี้แจงแก้ไขแล้ว โดยยอมรับว่าเทคโนโลยี AAAK ได้รับการยืนยันว่าเป็นการบีบอัดแบบสูญเสีย และให้คำมั่นว่าจะปรับปรุงเอกสารและการออกแบบระบบตามคำวิจารณ์ที่เข้มงวดจากชุมชน แต่เอกสารคำอธิบายหลักของโปรเจกต์ยังคงคงไว้ซึ่งคำกล่าวอ้างที่ยังไม่ได้แก้หลายรายการ รวมถึงการอ้างว่า “บีบอัดแบบไม่สูญเสียได้ 30 เท่า” และ “เพิ่มการค้นคืน 34%” และตารางเปรียบเทียบกับคู่แข่งรายอื่นก็ไม่มีแหล่งที่มาระบุไว้อย่างครบถ้วน
ซอร์สโค้ดของ MemPalace เผชิญกับบั๊กหลายรายการ
เมื่อมีผู้พัฒนามากขึ้นดาวน์โหลดไปทดสอบ ตอนนี้บนแพลตฟอร์ม GitHub มีรายงานบั๊กจำนวนมากเกี่ยวกับซอร์สโค้ดของ MemPalace
ผู้ใช้ cktang88 ได้ระบุข้อบกพร่องร้ายแรงหลายอย่าง โดย รวมถึงคำสั่งการบีบอัดที่ใช้งานไม่ได้และทำให้ระบบล่ม การคำนวณตรรกะจำนวนคำในบทสรุปผิดพลาด การจัดสถิติข้อมูลเพื่อขุดหา “ห้อง” ไม่แม่นยำ และทุกครั้งที่มีการเรียกใช้ เซิร์ฟเวอร์จะโหลดข้อมูลคำอธิบายทั้งหมดลงหน่วยความจำ ทำให้เกิดปัญหาการใช้ทรัพยากรอย่างหนัก
ปัญหาอื่น ๆ ที่ถูกชี้ให้เห็น ยังรวมถึงระบบที่บังคับเขียนชื่อสมาชิกในครอบครัวของนักพัฒนาลงในไฟล์ตั้งค่าเริ่มต้น และมีขีดจำกัดการแสดงผลแบบบังคับเมื่อดูสถานะการค้นหาอยู่ที่ 10k รายการข้อมูล
สำหรับปัญหาเหล่านี้ ชุมชนโอเพนซอร์สเริ่มลงมือแก้ไขอย่างจริงจังแล้ว ผู้ใช้ adv3nt3 ได้ส่งคำขอแก้ไขหลายรายการ****ซึ่งรวมถึงการแก้ไขสถิติการขุดหา การลบชื่อสมาชิกในครอบครัวที่ตั้งค่าไว้ล่วงหน้า และการเลื่อนเวลาการเริ่มต้นการสร้างแผนภาพความรู้ ต่อมาทีมพัฒนาก็ยอมรับข้อผิดพลาดเหล่านี้เช่นกัน และกำลังแก้ไขปัญหาโค้ดไปทีละขั้นผ่านความร่วมมือของชุมชน
Milla Jovovich สาย Vibe Coding เจ๋งมาก แต่แนวทางการตลาดไม่เจ๋ง
สำหรับโปรเจกต์ MemPalace ผู้ใช้ Hacker News ชื่อ darkhanakh ได้สรุปไว้ว่า: MemPalace ให้ความรู้สึกแบบ OpenClaw คือมีการ “จัดการ” ผลการวัดผล (benchmark) ให้ดูสมบูรณ์แบบโดยเจตนา แล้วค่อยนำมันไปห่อเป็นความก้าวหน้าครั้งใหญ่เพื่อทำการตลาด
เขามองว่า แม้เทคโนโลยีระดับล่างของ MemPalace อาจจะน่าสนใจจริง แต่ภายใต้สภาพที่วิธีทดสอบมีข้อบกพร่องลักษณะนี้ ยังนำมาประกาศว่าเป็น “คะแนนสูงสุดที่เคยเปิดเผยสู่สาธารณะ” เพื่อโปรโมตก็ไม่น่าจะเหมาะสมสักเท่าไรนัก “แต่แต่อย่างไรก็ตาม ตอนที่ Milla Jovovich เล่น Vibe Coding แบบนี้ ฉันก็ยังคิดว่ามันค่อนข้างเท่าดีอยู่นะ”
อ่านเพิ่มเติม:
AI เขียนโค้ดแล้วมีปัญหา! แอป “惜食獵人” ที่เป็นของหมดอายุในร้านสะดวกซื้อ โดนปัญหาความปลอดภัยข้อมูลรุม บ้านทั้งหลัง GPS โผล่หมด
