51.2 million lines of code, 1,906 files, 59.8 MB of source maps. In the early hours of March 31, Chaofan Shou from Solayer Labs found that Anthropic’s flagship product, Claude Code, had exposed the full source code in a public npm repository. Within a few hours, the code was mirrored to GitHub, and the number of forks surpassed 41,000.
This isn’t the first time Anthropic has made this mistake. When Claude Code was first released in February 2025, the same source-map leak happened once as well. This time the version number was v2.1.88, with the same cause: Bun, the build tool, generates source maps by default, and the .npmignore file forgot to exclude this file.
Most reports are tallying the “Easter eggs” in the leak—such as a virtual pet system and a “undercover mode” that lets Claude anonymously submit code to open-source projects. But the real question worth unpacking is: why does the same Claude model behave so differently in the web version versus in Claude Code? What exactly is it doing with 512,000 lines of code?
The model is just the tip of the iceberg
The answer is hidden in the code structure. According to a reverse analysis of the leaked source code by the GitHub community, in the 512,000 lines of TypeScript, only about 8,000 lines of interface code directly responsible for calling the AI model account for roughly 1.6% of the total.
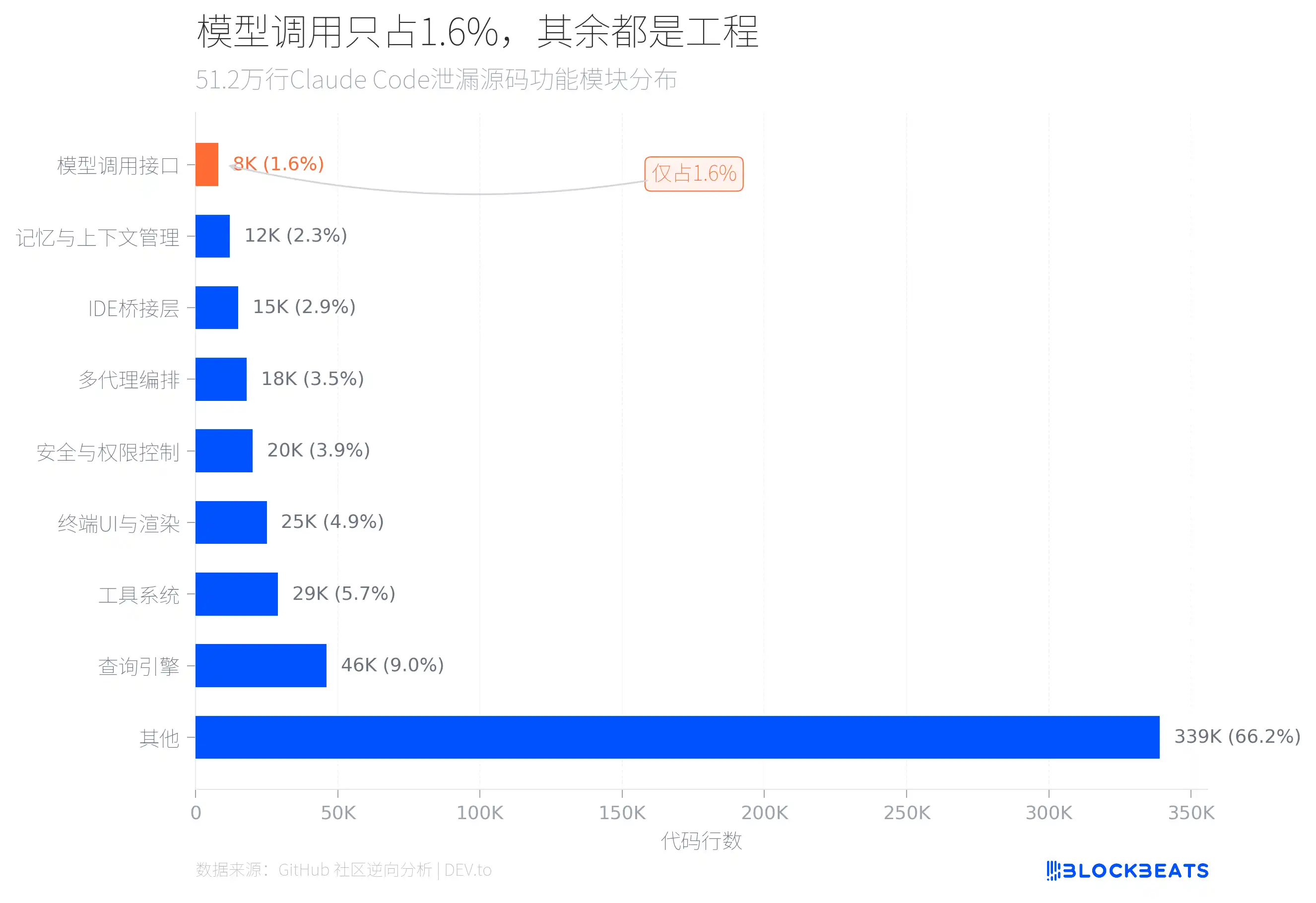
So what are the remaining 98.4% doing? The two biggest modules are the query engine (46,000 lines) and the tools system (29,000 lines). The query engine handles LLM API calls, streaming output, cache orchestration, and multi-turn conversation management. The tools system defines about 40 built-in tools and 50 slash commands, forming a plugin-like architecture where each tool has independent permission control.
In addition, there are 25,000 lines of terminal UI rendering code (one file called print.ts is as long as 5,594 lines, with a single function spanning 3,167 lines), 20,000 lines of security and permission control (including 23 numbered Bash security checks and 18 blocked Zsh built-in commands), and an 18,000-line multi-agent orchestration system.
After analyzing the leaked code, machine learning researcher Sebastian Raschka pointed out that the reason Claude Code is stronger than the web version with the same model isn’t the model itself, but the software “scaffolding” built around the model—including repository context loading, dedicated tool scheduling, caching strategies, and sub-agent collaboration. He even believes that if you apply the same engineering architecture to other models like DeepSeek or Kimi, you could also get nearly similar improvements in programming performance.
A straightforward comparison can help understand the gap. If you type a question into ChatGPT or the Claude web app, the model processes it and then returns an answer; when the conversation ends, nothing is left behind. But Claude Code does it completely differently: at startup it first reads your project files, understands the structure of your codebase, and remembers your preference like “don’t mock the database in tests.” It can directly execute commands in your terminal, edit files, and run tests. When it encounters complex tasks, it breaks them into multiple sub-tasks and assigns them to different sub-agents for parallel processing. In other words, the web version’s AI is a Q&A window, while Claude Code is a collaborator living on your computer.
Some people compare this architecture to an operating system: 42 built-in tools correspond to system calls; the permission system corresponds to user management; the MCP protocol corresponds to device drivers; and sub-agent orchestration corresponds to process scheduling. When shipped, each tool is by default marked as “unsafe, writeable,” unless developers explicitly declare it is safe. The file-editing tool forcibly checks whether you’ve read that file first—if you haven’t, it won’t let you change it. This isn’t just a chat bot with a few tools attached; it’s a runtime environment with an LLM at its core and complete security mechanisms.
This means one thing: the competitive moat of AI products may not be in the model layer, but in the engineering layer.
Every cache miss, and the cost goes up 10x
In the leaked code there’s a file called promptCacheBreakDetection.ts, which tracks 14 vectors that could cause prompt cache invalidation. Why would Anthropic engineers spend so much effort preventing cache misses?
Look at Anthropic’s official pricing and you’ll know. Take Claude Opus 4.6 as an example: the standard input price is $5 per million tokens, but if you hit the cache, the reading price drops to just $0.5—90% cheaper. Conversely, every time a cache miss happens, the inference cost has to multiply by 10.
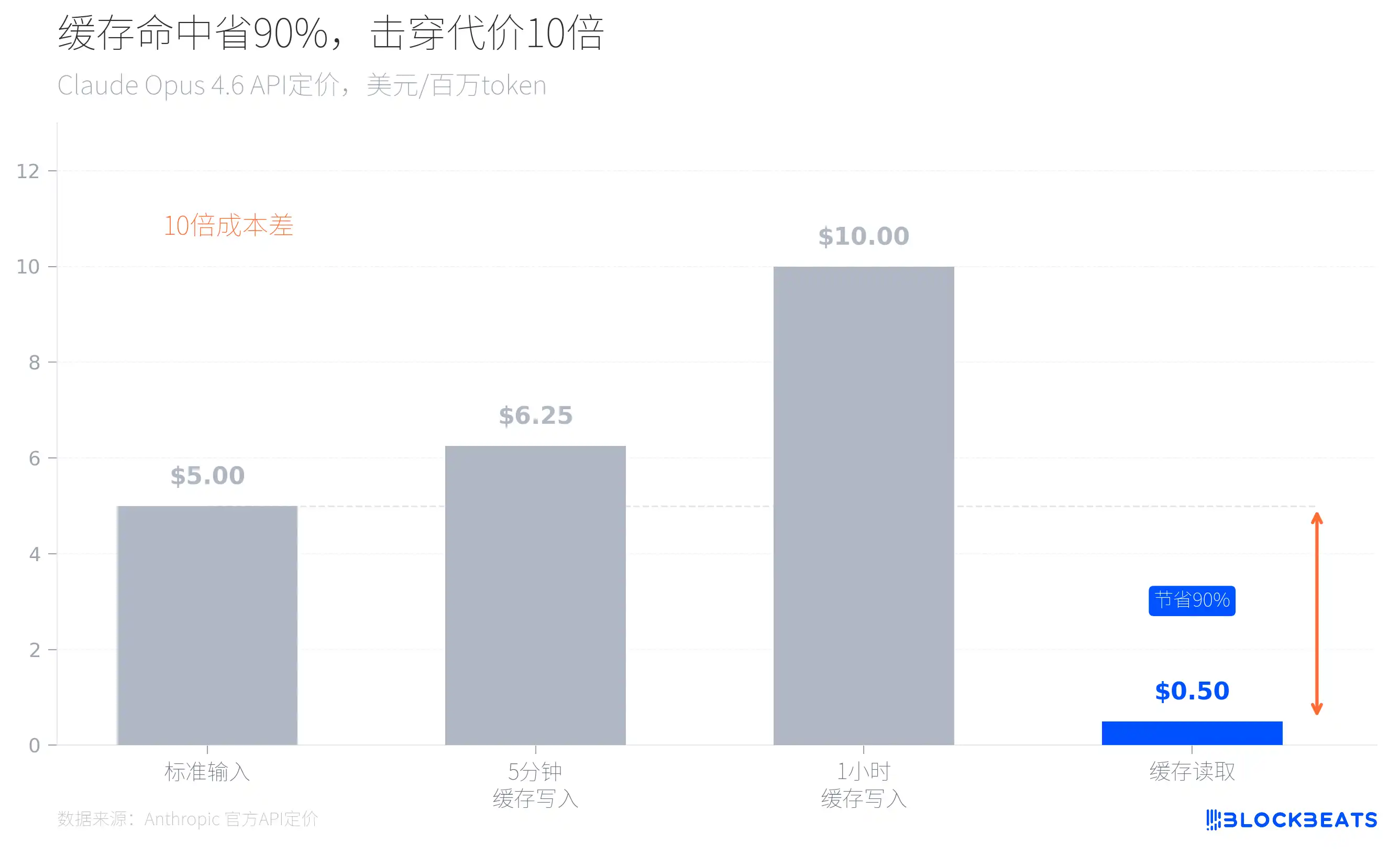
This explains a large number of seemingly “over-engineered” architectural decisions in the leaked code. When Claude Code starts, it loads the current git branch, the most recent commit history, and the CLAUDE.md file as context. These static contents are globally cached, separated from dynamic content using boundary markers to ensure that each conversation doesn’t reprocess already-known context. The code also includes a mechanism called sticky latches, which prevents cache damage caused by mode switching. Sub-agents are designed to reuse the parent process’s cache rather than recreating their own context window.
Here’s a detail worth expanding. Anyone who has used AI coding tools knows: the longer the conversation, the slower the AI response, because each turn requires sending the prior history back to the model. The usual approach is to delete old messages to free up space, but the problem is that deleting any message breaks the continuity of the cache, causing the entire conversation history to be reprocessed—driving both delay and costs up at the same time.
Within the leaked code, there is a mechanism called cache_edits. Instead of truly deleting messages, it marks old messages with a “skip” flag at the API layer. The model can no longer see those messages, but the continuity of the cache is not broken. This means that for a long multi-hour conversation, after cleaning up hundreds of old messages, the speed of the next response is almost the same as the first. For ordinary users, this is the underlying answer to “why Claude Code can support infinitely long conversations without slowing down.”
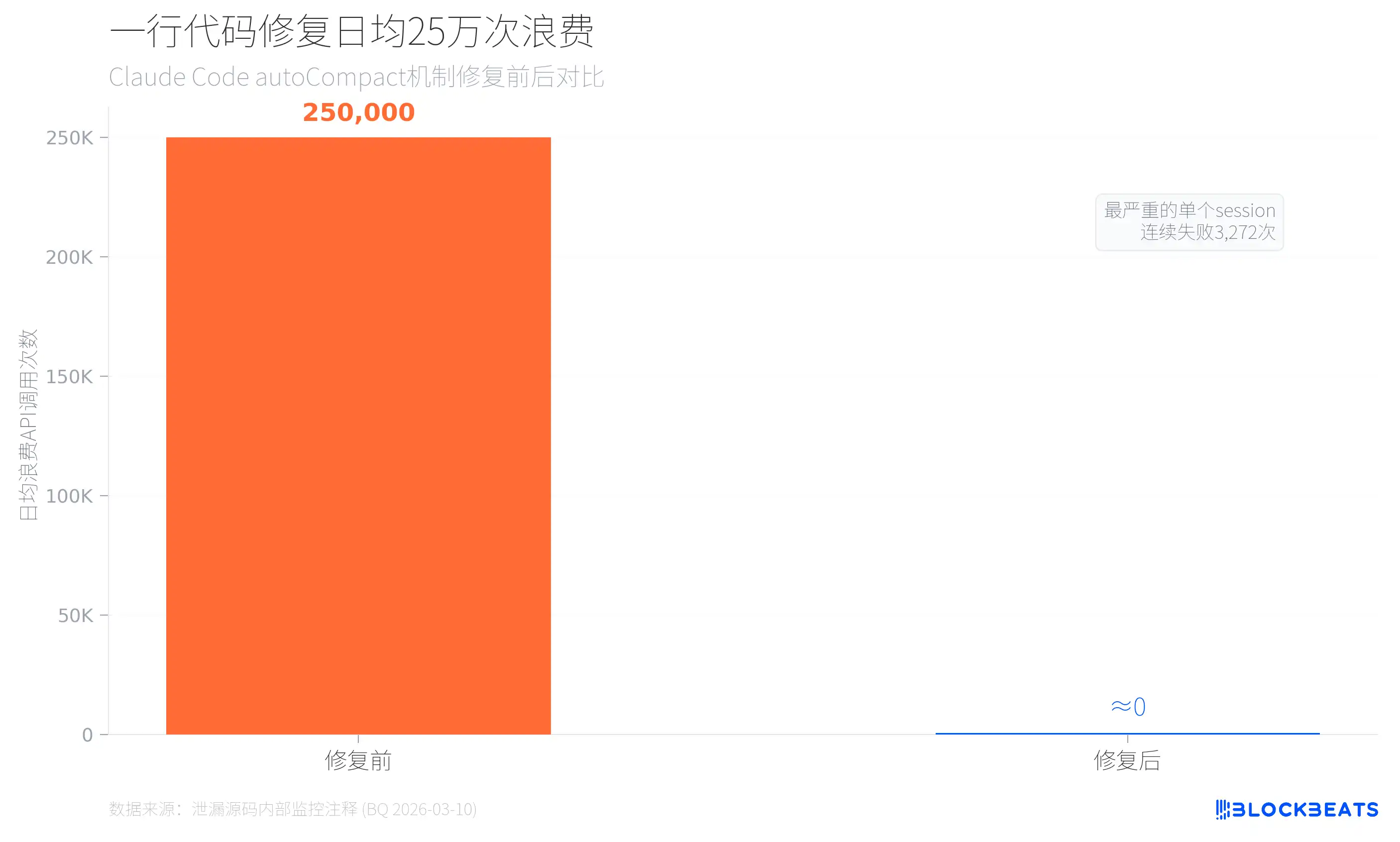
According to leaked internal monitoring data (from code comments in autoCompact.ts, dated March 10, 2026), before introducing an upper limit for automatic compression failures, Claude Code wasted about 250,000 API calls per day. There were 1,279 user sessions with 50 or more consecutive auto-compression failures, and the worst session failed 3,272 times in a row. The fix was simply adding a single line of restriction: MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3.
So, for AI products, model inference costs might not be the most expensive layer—cache-management failures are.
44 switches pointing in the same direction
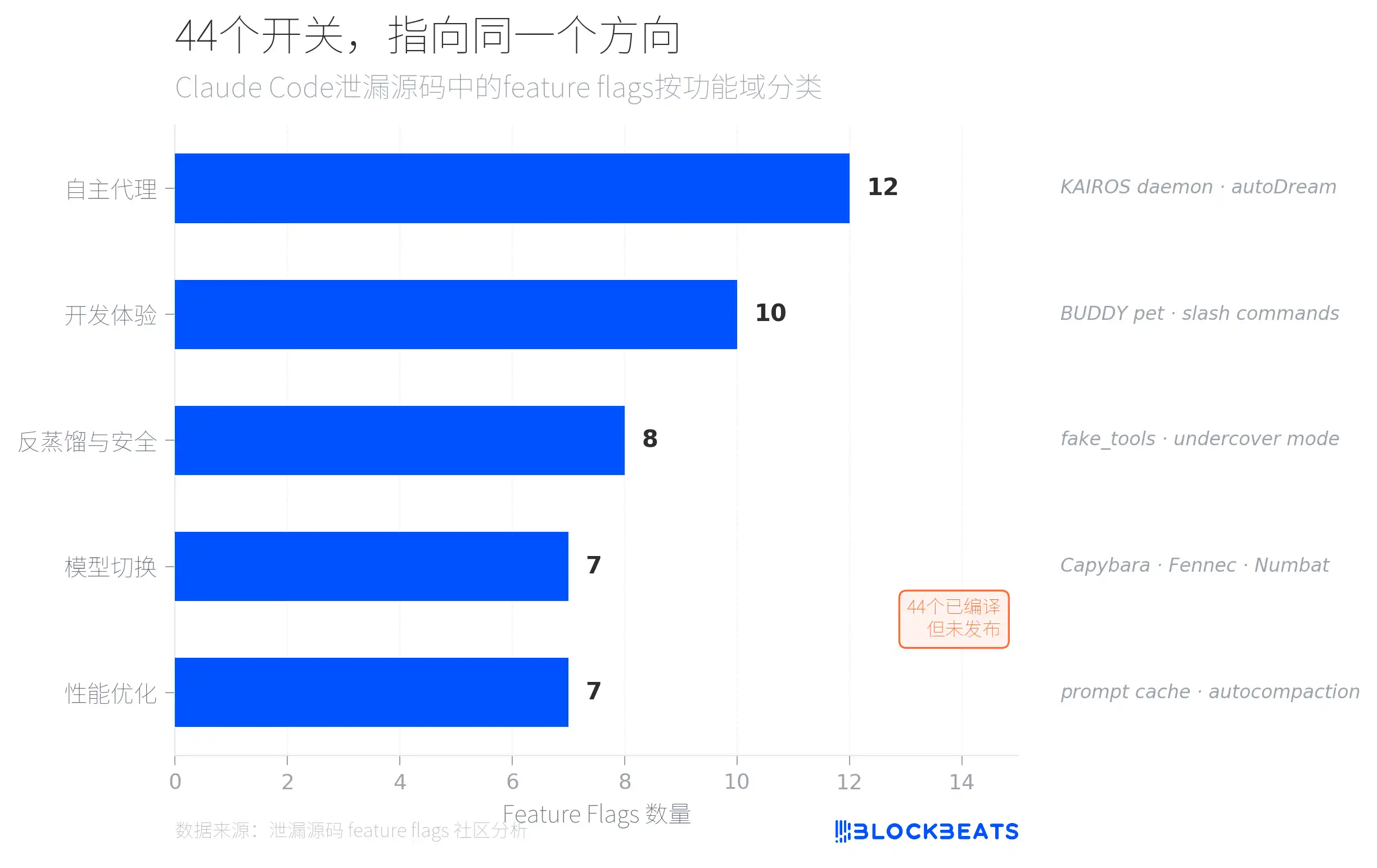
The leaked code hides 44 feature flags—functionality switches that have already been compiled but simply weren’t released externally. According to community analysis, these flags are divided into five categories by functional domain, and the most dense is the “autonomous agent” category (12), pointing to a system called KAIROS.
KAIROS is referenced more than 150 times in the source code. It’s a resident background “daemon process” mode. Claude Code is no longer just a tool that responds when you proactively call it; it’s an agent that runs in the background all the time—continuously observing, recording, and taking action at the right moment. The prerequisite is not interrupting the user: any operation that might block the user for more than 15 seconds is delayed.
KAIROS also has built-in terminal focus awareness. The code includes a terminalFocus field that detects in real time whether the user is currently looking at the terminal window. When you switch to the browser or other apps, the agent determines that you’re “not there” and switches to autonomous mode—actively executing tasks and directly submitting code without waiting for your confirmation. When you switch back to the terminal, the agent immediately returns to collaboration mode: first reporting what it just did, then asking for your input. Its level of autonomy isn’t fixed; it dynamically fluctuates with your attention. This solves a long-standing awkward problem with AI tools: fully autonomous AI makes people uneasy, while fully passive AI is too inefficient. KAIROS’s choice is to let the AI’s proactiveness dynamically adjust based on the user’s attention: when you’re watching it, it stays put; when you step away, it gets its work done on its own.
Another subsystem of KAIROS is called autoDream. After accumulating 5 sessions or every 24 hours, the agent starts a “reflection” process in the background, moving through four steps. First, scan existing memories to understand what it currently has. Then extract new knowledge from the conversation logs. Next, merge the new and old knowledge—correct contradictions and remove duplicates. Finally, simplify the index and delete outdated entries. This design borrows from memory consolidation theories in cognitive science. When people sleep, they organize daytime memories; when users leave, KAIROS organizes the project context. For ordinary users, this means the longer you use Claude Code, the more precisely it understands your project—not just “remembering what you said.”
The second largest category is “anti-distillation and security” (8 flags). The most notable one is the fake_tools mechanism: when 4 conditions are simultaneously met (a compile-time flag enabled, the CLI entry activated, using a first-party API, and the GrowthBook remote switch set to true), Claude Code injects fake tool definitions into API requests. The goal is to pollute datasets—possibly those recorded from API traffic and used to train competitor models. This is a brand-new form of defense in the AI arms race: not to stop you from copying, but to make you copy the wrong things.
In addition, the code also includes the Capybara model code name (split into three tiers: standard, fast, and million-context-window), which the community widely suspects is the internal codename for the Claude 5 series.
Easter egg: a digital pet hidden in 512,000 lines of code
Between all the serious engineering architecture and security mechanisms, Anthropic engineers quietly built a complete virtual pet system codenamed BUDDY.
According to the leaked code and community analysis, BUDDY is a “pet” that feels semi-physical, appearing in an ASCII speech-bubble frame beside the user input box. It has 18 species (including capybara, salamander, mushroom, ghost, dragon, and a series of original creatures like Pebblecrab, Dustbunny, and Mossfrog), divided into five rarity tiers: common (60%), rare (25%), epic (10%), legendary (4%), and mythic (1%). Each species also has a “shiny variant.” The rarest Shiny Legendary Nebulynx appears with a probability of only one in ten thousand.
Each BUDDY has five attributes: DEBUGGING (debugging), PATIENCE (patience), CHAOS (chaos), WISDOM (wisdom), and SNARK (snark). They can also wear hats, including a crown, top hat, propeller cap, halo, wizard hat, and even a mini duck. The hashed value of the user ID determines which pet you’ll hatch. Claude will generate a name and personality for it.
According to the leaked launch plan, BUDDY was originally scheduled to begin a closed beta from April 1 to April 7, and launch officially in May, starting with Anthropic’s internal employees.
512,000 lines of code, with 98.4% spent on hardcore engineering—yet in the end someone took the time to build a digital axolotl that wears a propeller hat. Perhaps that’s the most humanizing line of code in the leak.
Click to learn about the jobs at Lydom BlockBeats
Welcome to join the official Lydom BlockBeats community:
Telegram subscription channel: https://t.me/theblockbeats
Telegram group chat: https://t.me/BlockBeats_App
Twitter official account: https://twitter.com/BlockBeatsAsia
